Posts Tagged “client-side”
Follow
The right tool for the job, XSS edition
It is not very uncommon to see pages that include a “returnUrl” parameter, usually within authentication flows. At times, the browser will run some script (like a call to an analytics service) and then another script issuing a redirect (through setting location.href etc.)
There are also other cases where UGC can find its way into JavaScript blocks. People might want to have their script do fancy stuff with the page’s data.
var url = '<%=viewData.returnUrl%>';
or
var commenterName = '<%=viewData.newComment.authorName%>';
for e.g.
Now for the “stating the obvious”:
Just like any other UGC, this type of content must be sanitized to prevent XSS attacks.
Not to long ago I was called to do a security inspection on a web application’s codebase. During which, some very few XSS holes were detected using JavaScript injection. This was quite surprising to me, as I knew that all content injected into JavaScript was being sanitized by the team.
Digging further I found out that they did call a sanitize function on UGC, just not the correct function. What they did was to run a JSON formatter over the UGC string, a thing that was solving JS errors occurring from string quoting problems, but it did not eliminate malicious scripts.
The weird thing was that the team was already using the AntiXss library (which is a very aggressive, white list based input sanitation library for .NET), for html fragments. The library also have a JavaScript Encode function. Switching the sanitation function of the team from calling the JSON library to calling the AntiXss library fixed the problem for good.
e.g. code to demonstrate the difference between the methods:
static void Main()
{
var ugc = "';alert('xss');'";
Render(JsonConvert.SerializeObject(ugc));
Render(AntiXss.JavaScriptEncode(ugc));
}
static void Render(string encoded)
{
Console.WriteLine("var returnUrl = '"+encoded+"';");
}The output from the above snippet is:
var returnUrl = '"';alert('xss');'"';
var returnUrl = ''\x27\x3balert\x28\x27xss\x27\x29\x3b\x27'';
There are a couple of things to learn from that story:
- When you encounter a problem, look around for common solutions. for e.g., every language that is being used for web development today has a library that takes care of XSS, so use it instead of coming up with a partial solution using the wrong library, or even worse –try to re-invent the way of doing that. You are probably not in the business of Anti XSS, so don’t spend time on solving the problem.
- Know your toolbox. If you are using a tool, be aware of its capabilities (and shortages). Exploring the AntiXss library a little bit would have shown the team that there is a perfectly good solution for their problem.
Newlines in textarea are treated differently on different browsers
And guess who is the craziest one.
scenario
Client side validation is good right? so you have this field of User Generated Content, which is exposed via a textarea element on your page. For e.g. – comment on blog post.
Now you have a limit of N characters on the field, maybe enforced within a DB constraint or whatever.
First attempt:
function validateMaxLength(elmId) {
var element = document.getElementById(elmId);
var elementContent = element.value;
var elementContentLength = elementContent.length;
return elementContentLength <= N;
}or something like that.
BUT
think again.
Assuming the element’s content was something like
the element contains at least
one newline
how would you count newlines? would you count two characters per newline (for \r\n)? or only one?
When I faced that problem I checked how the browser is counting the newlines. I ran a quick test as saw that it counts newlines as a single character. Since the content was needed to be presented within a web element anyway, and newlines were to be changed to <br/> tags at render time anyway, I decided to have the server code make sure that incoming strings will use only \n for newlines, then validate the length, then store in the DB.
Now the client side JS matched the server criteria.
Case closed.
Or was it?
QA kicks in
After a little while I got a bug opened by the QA team about inconsistency between client and server validation regarding lengths of string.
Checked it, and was about to close the bug with a “works for me” message, but then it hit me.
You have to be so special
On IE, newlines are \r\n, so it reports too many characters, and the validation might fails wrongfully. Since I mostly use Chrome for day-to-day, and since I did not suspect that to be a cross-browser issue, I never tested it on IE during development.
Solution
Good old string.replace
elementContent = elementContent.replace(/\r\n/g,'\n');Ken,
the cross-browserer
Error – the current website’s developer is a complete moron
How lame can you get?
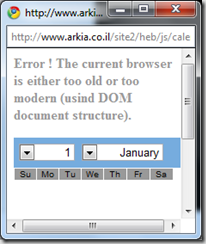
It is even misspelled.
The funniestsaddest thing is the source of this page:
<script language="JavaScript">
if (document.all) {
document.writeln(...);}
else {
document.writeln("<p><font color=\"#999999\"><b>Error ! The current browser is either too old or too modern (usind DOM document structure).</b></font></p>");}
</script>
So many bad practices in a such a small snippet. And the stuff in the (…) part was too painful to paste.
Javascript and the extended Array prototype
I do quite a bit of javascript stuff lately, and I wanted to enjoy the easier syntax of array methods such as forEach, find etc.
As the current project is not using prototype.js, but rather a different js stack (jquery, various jquery plugins, EJS, and a bit more) I did not have the extended Array stuff that comes with prototype.js
But before I ran off to add the needed methods to Array’s prototype, I had an annoying voice in the back of my head, whispering “extending Array’s prototype is evil, extending Array’s prototype is evil”, so I looked at alternatives.
Alternative 1 – subclassing Array. I went ahead to implement a MyArray (or Array2) type of solution.
using one method of JS subclassing I thought of
var MyArray = function() {
};
MyArray.prototype = new Array;
MyArray.prototype.forEach = function(action) {
for (var i = 0, l=this.length; i < l, ++i)
action(this[i]);
};
...
the problem with that approach is that IE does not like Array subclassing, thus the .length property becomes unreliable, rendering the whole idea of subclassing Array useless.
Alternative 2 – using a different object alltogether It would work, however things like
if (anArrayInstance instanceof Array)
will naturally break.
Alternative 3 – extend any ‘interesting’ instances
function extendArray(arr) {
if (arr.__wasExtended) return;
arr.forEach = function(action) {
for (var i = 0, l=this.length; i < l, ++i)
action(this[i]);
};
arr.__wasExtended = true;
}
which is wrong as any instance will get a copy of all the functions, so too much memory will be used for non-core functionality
Alternative 4 – use the separated scoped Array trick just read http://dean.edwards.name/weblog/2006/11/hooray/
the idea is to use an Array object from a separate iframe, thus enjoy the Array (instanceof), but not interfere with existing Array object on the main window
On top of all that. all three alternatives are problematic, as a regular
var a = [];
will not be extended. which is not such a big problem if you’re disciplined enough, but it’s terribly annoying to need to extend every array you want. think about JSON data you get from a service. you’d first have to iterate over the object graph and extend all of the arrays. yuck.
Now, do you remember that annoying voice from the back of my head? I decided to stand up to him !
Why actually not extend the Array prototype and be done with it?
It will solve the “instanceof” problem, it will solve the need to apply the functions manually on all arrays (as any [] will natively have the new functions), and it wouldn’t cost much memory as it will only be added to the single prototype of all array instances.
The usual reason for not wanting to do so, is that it would break the associative array ‘feature’ of javascript, and you won’t be able to
for (var i in myArray)
anymore.
You know what? that reason is a total bullshit.
Why? cuz there’s not such thing as an associative array in javascript !
If anything, the Object object is similar enough. However the Array object should be used with 0-based integer index, just like any native java/c#/c/whatever array.
Removing that ‘problem’ from the equation, and we can resort back to stuff like
Array.prototype.numSort = function() {
this.sort(function(a, b) { return a - b; });
return this;
};
Array.prototype.forEach = function(action, index) {
for (var i = 0, l = this.length; i < l; ++i)
action(this[i], index);
};
Array.prototype.find = function(func) {
for (var i = 0, l = this.length; i < l; ++i) {
var item = this[i];
if (func(item))
return item;
}
return null;
};
Array.prototype.where = function(func) {
var found = [];
for (var i = 0, l = this.length; i < l; ++i) {
var item = this[i];
if (func(item))
found.push(item);
}
return found;
};
You just have to love dynamic languages :)
Extracting text from a DOM element
I’ve just been asked the following question by a friend:
in javascript - how do i get the text of an html-element, which doesn’t include text of all the children? firefox only
Every html DOM element has a collection of direct children, called childNodes. Each node has a type, and text nodes (those are text portions that are part of an element’s inner content) have ‘3’ for their type.
So, the following code is the solution:
function extractFirstLevelTextFrom(elm) {
var text = '';
for (var i =0; i < elm.childNodes.length; ++i) {
if (elm.childNodes[i].nodeType==3)
text += elm.childNodes[i].nodeValue;
}
return text;
}
[not] storing data in DOM elements - jQuery.data function
At time you’d want to store data, related to a DOM element.
storing it directly into the element (either by elm.someArbitraryName = value, or with setAttribute) is wacky. Some browsers might not like you using non standard attributes, so you start using things like ‘alt’ and ‘rel’. Then again, these things has meaning, and storing arbitrary data is … well, uncool to say the least.
jQuery.data() to the rescue. As jQuery objects are wrappers that HasA DOM elements, and not the DOM elements themselves (as in prototype), storing data on them is like storing data on POJSO (Plain Old JavaScript Objects), and the data() functions allows for an easy way of doing that.
Read on that (and of a few other jQuery tips) at http://marcgrabanski.com/article/5-tips-for-better-jquery-code
Single and looking
explanation (before the wife kills me): I have some free time in the coming months, so I’m looking for interesting consulting gigs.
So, if you’re in a company / dev team, and looking for some help with Castle (Windsor, MonoRail), NHibernate, or general information system design and architecture advices or training, setting up build and test environments, or any other of the things I rant about in this blog, then I’m your guy.
I also do web-client ninja work, dancing the crazy css/html/javascript tango (jQuery: yes, Ms-Ajax: no)
I currently live in Israel, but I’m fine with going abroad for short terms if you’re an off-shore client.
you can contact me at “ken@kenegozi.com”
int.Parse != parseInt
Serving as a mental note, and as a service to dear readers who hadn’t been bitten by this yet.
javascript’s parseInt method is not the same as .NET’s int.Parse.
there’s this ‘radix’ argument which is meant to tell the parseInt method whether we want to treat the string we parse as binary, octal, decimal, hexadecimal or whatever.
Now the naive programmer (a.k.a. myself) would think that the default is always base 10, so parseInt(x) === parseInt(x, 10) for every x.
Apparently parseInt tries to outsmart us, and it’s actually guessing the radix if not set. so if x begins with 0x, it would guess hexadecimal, and if x begins with 0 it would guess it’s octal.
so, parseInt(‘010’) === parseInt(‘010’, 8) === 8
ok, I can live with that maybe.
however it would also ‘guess’ that 09 is octal (even though 9 is not an octal digit !) thus parseInt(‘09’) === 0
I found this by chance, when a Date.parse method I have was parsing "09/07/2008" into a date-info object with day==0, causing it to fall back into today’s date
So, the lessons we’ve learned today:
- javascript is not c#
- always set the radix when using parseInt - parseInt(x, 10)
- don’t let your cat spill a glass of soda on your desk as it would ruin your earphones, and unless the laptop was on an elevated stand it would have ruin it also
Box Model recap - this time in Hebrew
Over two year ago, I have posted about the un-orthodox box model that IE6 is using.
Yesterday I saw that Ohad Aston (an Israeli Web developer who blogs in Hebrew at the Israeli MSDN blogs site) has written a Hebrew explanation to the same phenomena, so if you do web, especially using ASP.NET and can read Hebrew, I recommend that you take a peek. And if you’re there, subscribe to his RSS. I did.
"Don't use bold, please use strong, cuz if you use bold it's old and wrong"
Another quote:
Please don’t use table even though they work fine,when it comes to indexing they give searches a hard time
and also
Check in all browsers, I do it directly, You got to make sure that it renders correctly
This should be in the curriculum for any webmasters 101 course
String.replace != String.Replace
I have a html tag (image input) with id that looks like “delete-party-image”.
On click, it should call XHR-ly to a server action, named DeletePartyImage.
Naively I did
var action = btn.id.replace('-', '');
which of course returned “deleteparty-image”, because, as opposed to .NET’s String object’s Replace() method, this one (javascript’s String.replace) only replaces the first occurrence.
Yeah, I already knew that, but have forgot it just when I needed it.
So for next time’s sake - the way to do it in javascript is using a regex with global modifier:
var action = btn.id.replace(/-/g, '');
I CAN HAS SITE - My LOL Blog, And Accessibility
There’s this cool little site that LOL-ify any web page.
This is how my blog would’ve looked like had I been a kitten. It would also most probably be written in LOLCODE.NET
Now, the interesting part.
I got that through Roy Osherove’s blog. That’s how his blog looks like when LOL-fied.
Can you see the difference?
When designing my blog’s markup, I paid good attention to the fact that the actual content (posts) should come before the side-bar with links, archive, blogroll, ads or whatever.
The more ‘legacy’ kind of web design (usually with tables, but can also be “achieved” with div/css) is to box everything around the content, and having the ViewContents (or ContentPlaceholder) as the last thing on the Layout (or MasterPage).
So when my blog is being read by a machine (that parses html), the important things is first.
You might say - I don’t give a crap about LOL sites, and my site is for humans, not machines.
But what about the blind who ‘reads’ helped by a machine that reads the page and say it out loud? must they get the whole links part on every page before they get to the content?
What about search index bots? we should help them get to the content.
Good News For Web Developers - IE7 Made It To Automatic Updates
The title say it all.
I really hope that IE6 would be obsolete as soon as possible. It would make writing decent markup much easier, not needing to look out for weird IE6 quirks. Also, won’t need to hack my way into look at pages in IE6 (since my machine has IE7 for some time now)
Last month’s IE visitors to my site (according to google analytics):
- IE7 - 64.46%
- IE6 - 35.47%
- IE5.01- 0.06% (WTF? who uses that?)
I really hope that soon enough IE6 would join IE5 in the not-important area.
btw, IE visitors in total are 45.51%, so IE6 visitors are only 16%. wow. that’s good, especially since the DotNetKick widget does not render well on IE6 and I never found time to fix that. I guess I’m not going to …
YUI ColorPicker Within a non-posting Floating Dialog
My personal preference in javascript framework is prototype + YUI.
I take the language enhancements of prototype (enumerable/array, extend, $/$$), and the richness of widgets and event handling of YUI. One might say that prototype is my Javascript2, and YUI is the BCL.
These days I’m with YUI 2.4.1 and prototype 1.6.0
This week I needed to put floating color pickers on a few screens in a system.
Usually, the easiest thing would be to copy a pre-existing demo fro YUI docs. However, the color picker in dialog demo there was about the dialog posting to the server it’s results, while I needed just to save the value into form fields.
The sample also uses a preexisting markup, which was not good in this scenario.
Plus, since the said system have a very complicated (and fragile) styling and scripts happening on many pages, strange things have happened to the dialog if ran more than once on the same page, so I’ve added a “destroy” method that would cause the dialog to be rebuilt each time. It’s lightning fast, and has no visible effects on the user experience.
Another major change I’ve made to the sample, is the use of methods on a ‘global’ static object (CP) instead creating an instance of a function() and add the methods there (like the guys at YUI likes). The latter is nice in it’s increased encapsulation, however the need to deal with the scoping issues is making event registration and event handlers too awkward imo.
Anyway - that’s the code, you can use it as you will. Just remember it’s “as-is”, “no-warrenty” BSD thing.
YAHOO.ColorPicker = {};
// aliasvar CP = YAHOO.ColorPicker;CP.dialog = null;
// creates the dialog with a color picker insideCP.createPicker = function() { CP.dialog = new YAHOO.widget.Dialog("yui-picker-panel", { width : '500px', close : false, fixedcenter : true, visible : false, draggable : false, modal : true, constraintoviewport : true, effect : { effect : YAHOO.widget.ContainerEffect.FADE, duration : 0.2 }, buttons : [ { text:"Done", handler:this.handleOk, isDefault:true }, { text:"Cancel", handler:this.handleCancel } ] });
// dialog markup: CP.dialog.setHeader('Pick a color:');
// placeholder for the color picker CP.dialog.setBody('<div id="yui-picker" class="yui-picker"></div>'); CP.dialog.render(document.body); $(CP.dialog.element).addClassName('yui-picker-panel');
// create the picker CP.picker = new YAHOO.widget.ColorPicker("yui-picker", { showhexcontrols : true, showhexsummary : false, images : { PICKER_THUMB : "/common/javascript/yui/colorpicker/assets/picker_thumb.png", HUE_THUMB : "/common/javascript/yui/colorpicker/assets/hue_thumb.png" } });}
// in here I have used prototype to get the hex data. you can of course use
// YUI's getElementsByClassName, jQuery, or your own method.CP.handleOk = function() { var hexField = $(CP.dialog.element).down('.yui-picker-hex'); var hex = hexField.value; $(CP.targetId).value = '#' + hex; CP.dialog.hide(); setTimeout(CP.destroy, 300);}
// removes the dialog completelyCP.destroy = function() { CP.dialog.destroy(); CP.dialog = null;}
CP.handleCancel = function() {
CP.dialog.cancel(); setTimeout(CP.destroy, 300);
}
// create the picker if needed, set it's value, and show
CP.showPicker = function(ev) { if (CP.dialog === null) { CP.createPicker(); } var target = ev.target || ev.srcElement; CP.targetId = target.id; var val = target.value; if (val.match(/#?[a-fA-F0-9]{6}/)) { if (val.indexOf('#') === 0 && val.length > 1) val = val.substring(1); CP.picker.setValue(YAHOO.util.Color.hex2rgb(val)); } CP.dialog.show();}
// registering the pickers on our color fieldsYAHOO.util.Event.onDOMReady(function() { var fields = YAHOO.util.Dom.getElementsByClassName('color-picked'); YAHOO.util.Event.on(fields, "click", CP.showPicker);});
You can try to clean the CP.destroy method and see if it works for your scenario.
hmm, ofcourse, needed YUI files are:
- utilities/utilities.js
- container/container-min.js
- slider/slider-min.js
- yui/colorpicker/colorpicker-beta.js
- fonts/fonts-min.css
- container/assets/container.css
- container/assets/skins/sam/container.css
- colorpicker/assets/skins/sam/colorpicker.css
A little markup+css challenge
After reading the challenge on Dror’s blog (Hebrew) I decided to post my answer here.
In short, for non hebrew readers, Dror is asking for a markup+css solution for the next layout:
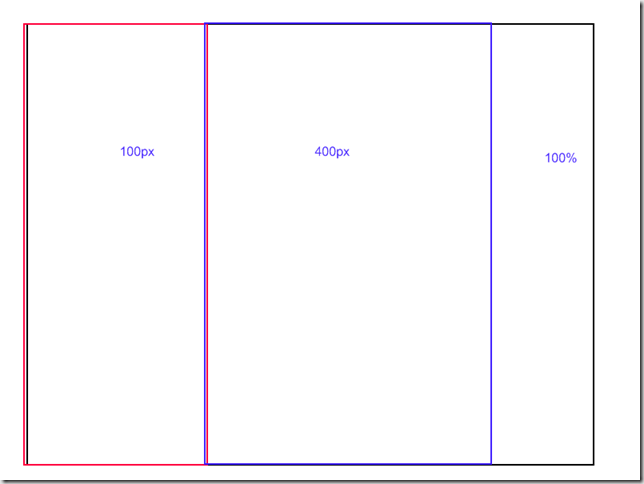
no javascript allowed for layout purposes.
Oh, and the center column can be long, so the left and right columns should stretch with it.
I have added another prequisite: the center content must come before the side contents (for accessibility).
That’s my simplistic answer:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional-dtd"> <html xmlns="http://www.w3.org/1999/xhtml"><head> <title>Dror Engel's blog rocks</title> <style type='text/css'> div, body {padding:0, margin:0} #right-column { background-color:#FFA }
#left-column { float:left; width: 500px; background-color:#FAF }
#center-column { float:right; width:400px; background-color:#AFF } div.break { clear:left; }
</style> <script type='text/javascript'> function stretchCenter() { var center = document.getElementById('center-column'); center.innerHTML += '<br /> Blah blah blah'; } </script></head><body> <div id='right-column'> <div id='left-column'> <div id='center-column'> <button onclick='stretchCenter();'>Streach Center</button> <br /> Center <br /> Center <br /> Center <br /> </div> Left </div> right <br /> <div class='break'></div> </div></body></html>
demo is here.
On Potty Mouths, or Fuck Those Leaky Abstractions
Reading David Heinemeier’s post, it got me thinking.
In short (my words):
Since the meaning is what important, it doesn’t matter whether you use Curse Words or their ‘polite’ euphemisms. The saying ‘What the fuck is that’ represents an honest question, while saying ‘We should exile all those socially challengedforeigners’. Using Politically-Correct words in an outrageous sentence is much worse than a naive ‘It’s fucking great’.
Favorite quote from David’s post:
…fake euphemisms that are actually much worse than the honest words they’re trying to put a fig leave to.
Anyway, while thinking about that, a (bit far fetched) analogy came to my mind.
Many developers refer to ‘HTML’, ‘DHTML’ and ‘Javascript’ as curse words.
So they come up with euphemisms like Script#, RJS, WebForms and others, and by that, applying badlyleaking abstractions on top of simple things. (HTML and Javascript are quite simple. you can see 13 year old kids that master those, but much less 13 years old master server OO languages).
Funny anecdote:
Writing this post on Windows Live Writer, the spell-checker is pointing out that ‘fuck’ is a misspelled word. One of the fix suggestions though is ‘suck’ … Ha Ha.
IE7 to the masses - the end of IE6 compatibility issues?
That’s a great news for everyone who build websites and web applications.
IE7 would be installable even to XP users without the Genuine Check.
That means that in short time, the IE7 adoption rate would increase so much, that hopefully the annoying IE6 would become as obsolete as Netscape 4 and IE 5.5 …
No more dirty CSS hacks (or at least, a lot less)
No more buggy box-model
Finally we can use input[type=text] and the likes
I’ve kept IE6 on my box for so long only to be able to test what I write. Even though I use Firefox for day-to-day browsing, I still need IE for some crappy israeli sites that would just not work on non IE (and by not work - I mean that you get an alert box saying:
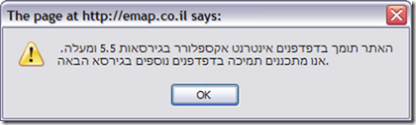
For people who knows not Hebrew:
“This site supports IE browsers, from version 5.5 and up. Support to other browsers is planned for next release”
Ha Ha.
This message is there for at least a year.
And it’s not even dependant on ActiveX or other IE magic. It’s only some laziness regarding JS and CSS compatibility.
Does Javascript / CSS / HTML Suck?(**)
Well, it depends who you’re asking.
It also depends on how good you look, apparently.
If you’d ask John Bristowe he’d say YES.
If you’d ask a good-looking software consultant such as Justice Gray, he’d just get angry at John.
Now, seriously, my view on that:
Javascript is a GREAT language.
It’s VERY easy to work with(*)(and I mean, to do DHTML, not to write a WorkFlow engine or an OR/M).
You can O.O with Javascript, you can get functional, you’re a dynamic as you can get, and it’s THE most cross-platform thing today. It’d work exactly the same on every PC and MAC operating system from the last twothree five years.
Of course, lousy developers can write javascript code that would work only on FireFox, or only on IE6 and a XP machine without SP2 that was installed on a full moon Thursday evening.
But note that these kind of developers won’t be able to code a fizz-buzz in C/Java/C#.
And that’s what so great about javascript.
It works even for idiots.
(*) It is. Just throw prototype.js (or any other) and you’re a king. You say “it’s not fair”? well, that’s the whole point. Extending javascript from a “regular” one to a “prototype.js” one is possible, and even not that hard. Now try to do that for Java/C#/Whatever.
(**) The answer is No. If you haven’t guessed that by now, then forget about Javascript. Hell, forget about programming all together.
Better Tips for Improving ASP.NET Performance
So you say “Hey Ken, that’s not fair. Ranting about the bad performance tipsisn’t good enough. We want GOOD tips”.
I won’t say that those are necessarily GOOD tips, however they are probably BETTER.
without further ado, I’ll quickly pull out of my hat my somewhat better tips:
-
Learn to use caching, both for dynamic and static content.
-
TURN OFF ViewState (and ControlState). Find better solutions. Really. You do not need the viewstate to get txtName.Text. Just use the damn Form[“txtName”], or writeTypeSafe wrapper around the Form (or Request.Items) collection.
-
Learn SQL.
-
Use caching.
-
ADD Client-side validation to the Server side validation. DO NOT remove server side validation, as every javascript beginner can bypass client-side stuff.
-
Avoid SELECT+N.
-
Cache responses where appropriate.
-
Have as least external files as you can. Join all .js to one file. join all .css to one file. It takes a LOT more time for the browser to open a connection to the server, that to actually get those lousy extra 5k. And out-of-the-box, browsers can have a maximum of 2 connections to the server at once.
-
Cache DB queries when appropriate
-
Enable GZip on IIS
-
Use the “COUNT” keyword in SQL, rather than the”Count” or “Length” .NET properties
-
Did I mention caching?
-
Avoid Page where it can be replaced with an IHttpHandler. That code is BAD:
public class SomePage : System.Web.UI.Page{ protected void Page_Load(object sender, EventArgs e) { Response.Clear(); Response.Write(something); }}
Bad Tips To Improve ASP.NET Application Performance?
Wow.
Take a look at that tip sheet.
Are these guys serious?
Best quotes:
3. Avoid Server-Side ValidationTry to avoid server-side validation, use client-side instead. Server-Side will just consume valuable resources on your servers, and cause more chat back and forth.
huh?
12. Caching is Possibly the number one tip!Use Quick Page Caching and the ASP.net Cache API! Lots to learn, its not as simple as you might think. There is a lot of strategy involved here. When do you cache? what do you cache?
if it’s no. one tip (and it is), why is it numbered 12?
20. Option Strict and Option ExplicitThis is an oldy, and not so much a strictly ASP.net tip, but a .net tip in general. Make sure you turn BOTH on. you should never trust .net or any compiler to perform conversions for you. That’s just shady programming, and low quality code anyway. If you have never turned both on, go turn them on right now and try and compile. Fix all your errors.
what’s that has to do with performance?
I just can’t believe that CodeProject has linked to that article.
Where's that "feed" link on live spaces?
Today I wanted to subscribe to the feed of Scott McMaster’s blog (an excellent one, and a must read for WebForms developers).
Crappily enough, I found no visible feed/rss/whatever link on the page.
Luckily enough I’m using FF2 and I get the tiny feed icon on the address bar, soI could click it. Not lucky to all the poor fellows that still use IE6 and the likes (hey - get a valid copy of windows, or sack the IT guy who is afraid of upgrade, whatever’s keeping you in the evil grip of the quircky browser)
So what should you do if you are that poor fellow?
view the page’s source (that’s “right-click + View Source), and look for a link tag within the <head> that sais
<link rel="alternate" type="application/rss+xml" title="THE SPACE'S TITLE" href="THE FEED LINK" />
now, if you’ve looked for the exact string written here you’re hopeless, and should read a html book / w3schools sitebefore you start ‘hacking’ html.
Web development != Windows development
Ok, I hope I’m not falling for a fruitless debate here, but after reading Scott’s post about the impending death of HTML, and giving my notes on that, I’ve read his another post, now about “why you should only do windows development”.
First of all - his blog is very good and interesting, and it’s on my favorite feed reader now. Try and guess which one I use based on what you read here.
Regarding Scott’s post, I’d like to mention two noticeable quotes:
It’s amazing how much time and energy are put forth by people (yours truly included) trying to make the browser user experience more like what you could achieve with Visual Basic circa 1994, let alone Windows Forms or Swing circa 2007
and
Which begs the question of why folks are producing so many new browser-oriented applications in the first place. But that’s another post for another day.
Well, I concur. You should not try to imitate VB apps in DHTML.I can’t see a possible for a decent Visual Studio replacement purely in the browser.
However, there are WEB applications, that a light-speed, no-install-needed, runs-on-every-machine-exactly-the-same website (gmail?) would beat any desktop app (Outlook? Thunderbird?) easily enough.
Let’s think of another true WEB application. Blogging.Let’s say you were using a blog-engine with no HTML front. you’d assume your readers are running SilverLight/Flash/whatever, or have ClickOnce enabled with the appropriate .NET framework installed, or rather enough user-rights to make it work, or mac? or Java?
So, okay. Let’s say you’d go with Flash - EVERYONE RUNS FLASH, right? well, almost everyone. But, come-on, tell all those c#/Java/Ruby guys that the need to switch to ActionScript? (or flex or any other flavour)? good luck with that.
Silverlight? promising, however in early Alpha.
ClickOnce - How many web sites using that do you know of? Even in Intranet environment you get IT people who are not willing to allow it.
Java? well it is on almost any machine today. Silver Bullet? Well, it doesn’t take a Ruby developer to avoid Java. you can’t get more static-typed than that, plus most java IDEs (but eclipse) suck big-time. I’d really rather use a text editor (even Edit.exe) over the OC4J bundle for example.
But, let’s assume that VisualStudio for J2ME is out,(with R# 4), and everyone WANTS to write applets.
So you now have a “blog applet” and allmost some of your readers can actually read your blog.
Wait a minute, you want to change the font facefont color layout of the blog. How do you do that in Java? and how would you have done it if your blog’s layout was dependant on a simple CSS file (the ultimate DSL imho)?
My point is - Web development is web development. It’s as widespread as it gets. everyone can easily embed a html rendering engine into an application to make plugin support easy (all those vista/google/yahoo kawagadgets? html within the media players? custom buttons in WindowsLiveWriter), so the HTML/CSS/Javascript stack is: a. Everywhere and b. Easy to customize. Sounds like Web to me.
Think that every10 year old geek who have wanted to customize his cool myspacefacebook whatever page should have learned swing/WinForms/Programming to do that?
In short:Writing desktop apps using DHTML is stupidWriting Web apps using java/winforms/etc. is stupid.
No silver bullet, they both have their ups and downs.
Photoshop? Win
Blog/Forum? Web
Any other? Contextual
Oh, and it’s Google Reader, if you’ve had any doubt.
HTML, Assembly, and in between
Ok, so I’ve read Scott McMaster’s post where he made some comparison between HTML and Assembly.
My first reaction had been: “Must be another of those HTML frightened guys”. I knowI have been one in the past.
But then I’ve read the small debate that evolved around that post, over at Ayende’s blog, and I understand Scott’s point better (even though I totally disagree, for the reason so beautifully written by Faisel).
Now I’d like to refer to the”Need of abstraction” for all those “I’m scared of HTML”guys.
HTML is easy.
Really.
Ask any 12 year who’ve read a “Build your webpage” book.
Ask any decent web designer who can hack together flying menus and 3d buttons without knowing the difference between ‘for’ and ‘while’.
Browser compatibility issues? You kid me? w3schools + quircksmode, and thanks to FF+Safari+IE7 it’s becoming less of an issue by the day.
Css? that’s really a bright idea. Very intuitive and meaningful. The ultimate DSL.
The only ‘problem’ is Javascript, that wasn’t maturing fast enough in terms of a standard library, but thanks to prototype and the likes, and since Steve-Yegge announced that NBL is Javascript 2.0, hopefully the browsers soon would implement some stuff to make Javascript the great language it should be in a standardized way.
Building a html/css combination to comply with a crazy designer’s psd is a child’s play. Adding an advanced “sort the grid, and do some async web calls” is easier than writing your own Data Access code correctly. I saw a lot more of a bad data access code than bad DHTML code, and since most Data-Access code is private while most DHTML code is wide open in the wild, I must conclude that it must be easier to make a website’s UI work than to have connections open-late and close-early.
Remember,I was a web-scared guy for a long time, and Asp.NET 1.0 with it’s ViewState and int.TryParse(txtAge.Text, out age) was the entry point to the browser for me. It took a lot for me to understand that I must learn HTTP, HTML and Javascript, and shockingly enough I realized thatit’s a far simpler model than the so-called “abstraction” of WebForms.
And in the future?
Silverlight/Flex/whatever could have been the future, but it surly ain’t the near one. It’s a matter of standards. xhtml 1.1, CSS 2, Javascript 1.2,those are standard. The differences between Safari, FF2 and IE7are minimal nowadays. It would take a lot of time (imho) until most web-sites would run purely on abrowser runtime thing. Not to mention that XHTML is cross platform down to almost any device these days. and that the textual nature of XHTML makes it very fast, and supportive of the “Let’s index all knowledge over the WWW” thing that some small start-up companies (like Google) are pushing.
That was one of the strangest rants I’ve ever done.
ASP.NET Ajax UpdatePanel Challenge
Actually, it’s not much of a challenge, but it is a catchy title.
Or is it?
Anyway, that’s the details:
I’d kindly ask all of you ASP.NET Ajax wiz guys (and gals), to supply me with a simple UpdatePanel thing.
What should it do?
I want to have a webpage, based onthis template, that on dropdown change, will go to the server with the selected value in the dropdown, and update the data (table) with some crap, based on the sent value.
You can leave the actual data retrieval to a simple method returning an array of string array, or you can go and implement a CodeSmith/DAAB/Whatever based supercool data access code. I would ignore it anyway. I want the Ajax stuff.
Now, to the why.
I am doing that MonoRail presentation at Microsoft’s Israel IVCUG (Israel Visual C(#/++) User Group) next week. I might be showing some demos, and I want to be fare when I show a comparison to WebForms stuff, and not come up with a crappy code and say “ha ha”, but show something that one of you, my-dear-readers-who-actually-uses-asp-net-ajax-for-living, wrote, and is considered a good example.
Also, I’m lazy. Seriously. Creating a presentation takes a LOT of time and effort, and I do not have much of the first, and rather avoid much of the later.
So, please do send me that code, to my-first-name at that-blog’s-hostname.
thanks.
Javascript Debugging in VS2005, VS2003 and InterDev is a no go AFAIC
Regarding my last post on the matter, Justin has commented with:
Javascript debugging has been around since VS2003.It’s not the most obvious or straight forward as in VS2008, but it’s pretty easy.The “Script explorer” window in VS2005 lets you see all the files downloaded for a certain browser process Visual Studio is currently attached to. From those files you can set a break point. So yes, it wasn’t easy, but it isn’t ground breaking either.
Josh took it one step further mentioning Visual InterDev.
I consider myself a rather sophisticated user, especially when it comes to IDE of any kind.
However, I did not use Javascript Debugging in VS2005 and VS2003, for the simple reason that it was not easy enough, and did not give me enough knowledge of the runtime vars etc. while using it.
When I started .NET-ing, I’ve had no VisualStudio license, and no idea about SharpDevelop. So I used notepad + csc.exe + WinDbg.exe . It’s workable, but it sucks. Just like JS debugging in VS.
Since javascript runs in the client, on the generated markup files, and not on the server’s templates (aspx, whatever), it’s not as useful as FireBug’s ability to set a breakpoint on a proper client html file.
Now, quoting from ScottGu’s post:
f you add/remove/update the breakpoint locations in the running HTML document, VS 2008 is also now smart enough to perform the reverse mapping and update the breakpoint in the original .aspx or .master source file on the server. This makes it much easier to get into a nice edit/debug/edit/debug flow as you are iterating on your applications
As I said - my main reason to move to VS2008 is it’s multi-target support, and js intellisense. Sure, I can get js intellisense with a lot of cool non-MS tools, but I want to have a single IDE window per solution.
The easier js debugging IS ground breaking for me, as it seams that I’ll be able to use it for debugging js in IE, a thing I’m not currently doing with VS since I don’t like it so much.
Javascript Debugging Made Easy, Even In Internet Explorer
This is why I’ll be switching to VS2008, if That was not enough.
As Scott keeps reminding us, it (VS2008) will be able to target multiple runtimes, so we can keep using that against .NET 2.0 and .NET 3.0, no need to adapt 3.5 yet. (I wonder about targeting Mono from VS 2008 …)
Until now, the JS debugging in VS was not too nice. Sure, I can use FireBug, and thanks to PrototypeJs I have almost no browser compatibility issues. However, sometime IE behaves strange, and I havn’t found any decent way to breakpoint into js in IE.
VS 2008 Javascript Intellisense + PrototypeJs => isFunToScriptBrowsers == true
Checkout the latest post of Scott Guthrie.
Is the long awaited JS IDE will be VS2008?
Now it’s a matter of adding ///<summery> tags to prototype.js and maybe people would really stop being afraid of developing javascript code.
Now that’s a good reason to switch to VS2008, combined with the fact than you can hold to your current .NET distribution.
Google Gears - Local storage and Offline mode for Rich Internet Application
Wow.
Another great tool from Google.
Works on Win/Mac/Linux, for IE and FF.
In a few words - it can give you offline browsing, plus local storage using SQLite (so you can run SQL queries strait from your javascript to query the local store)
I wonder what secutiry issues can come up. However, it looks very cool, and can help bring power to existing DHTML/Ajax apps.
Makes me think. Now that you do SQL from javascript, isn’t it time forJsHibernate? and what about an ActiveRecord inplementation in javascript?
So, in the Flex/Silverlight war, it seams that Google is gonna win again …
(from Scott Hanselman’s Blog)
Is XAML and WPF are really that cool?
I am considering WPF-ing a new component for one of are in-house projects. So I’ve done some reading, and to be sincere, I am not too excited.
Let’s refine the last statement. I am very excited with the technology. However, I find the examples out there very annoying.
It all seams to be “Hey it’s so cool !! I can do stuff IN THE MARKUP - woosh, god save XAML”.
So I came across this post.
It is just great!! it shows how I can easily use only 13 lines of XML to showa grind ONLY if the source is not null.
Sure a lot more expressive and easy than, say:
if (source != null) mySuperCoolGrid.DataBind();
DTD PUBLIC strings are case sensitive
I have just tried to do a xhtml validation on a site I’m working on (@ http://validator.w3.org), and I got some pretty wierd errors. It turned out the the DTD was not accurate, since the PUBLIC section contained lowercase characters.
So the right DTD for XHTML 1.1 is:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/tr/xhtml11/Dtd/xhtml11.dtd">
Now it passes the validation.
My first CodeProject article is up
I’ve posted an article to CodeProject about building my Google Ajax Search EnabledHomepage.
So, go there, read it, comment it, vote for it, tell your friends about it, print it and glue it to your forehead, whatever you think is appropriate.
Unless you didn’t like it. In that case, you shouldn’t do anything. why bother ? :)
Google AJAX Search API and My New Homepage
I have loaded a new homepage, and used a little of the Google AJAX Search API to make it interesting. Actually, I’m using it now as my browser’s default homepage, instead of google.com
Not only that, but I have documented the process of making it, and have sent it to codeproject, to be published, as my first contribution there, in hope for more to come.
So, please leave your impressions, eiether here or in the codeproject article (I’ll post the addresss once it will be up).
Things I've been doing lately
I’ve been off the radar lately, due to some extensive work I do on a website for my employer.
It is still in early stages and I cannot talk about the site itself, but I can talk a little about the technology that drives it.
In one word: Castle.
In a few more words:
Data Access and OR/m: Castle’s ActiveRecord over NHibernate
Web UI Engine: Castle’s MonoRail
ViewEngine: AspView (by yours truely, inspired by Ayende’s Brail). All my spare time from work goes there.
Client Side Javascript stuff: Prototype and Scriptaculous.
I really believe in the efforts made by Castle group, and I hope the the site I’m working on will be successful, as to serve for yet another prove of concept.
One more thing I’m doing last month, is that I’ve decided to finally end the thing with my Bachelor’s degree. I needed to retake Linear Algebra I (yep, that one the all the non-bullet-time Matrixes … I H-A-T-E adjoined matrixes. yuck) so that’s actually why AspView doesn’t progress as I’d want it too (and as some of my readers want, too).
Atlas naming game
There is a nice post about naming the Atlas package, at http://aspadvice.com/blogs/ssmith/archive/2006/08/16/Atlas_Naming_Game.aspx
There are some funny comments there, so do not miss.
And that is my comment:
“I think that too descriptive names suck.
I’d go with any non-descriptive name, such as the ones MS uses as codenames (I loved Avalon and so on).I believe that from the marketing point of view, non-descriptive catchy names ar far better than the others.It’s like dice.com and monster.com doesn’t include “job” in their name.
But since MS are determined to use descriptive names, at least they should concentrate on the “what” and not on the “how”.so “Async XmlHttp Enabled Web Apps” (AXEWA ?) is bad, while “Dynamic Web Browsing” is better.”
Understanding the Box Model of html elements
I’ve just came across some issue that can drive anyone who try to design a web page, that won’t be viewed differently on more than one targeted browser.It’s our furtune that most our clients are in Israel, where everyone uses IE, but the increasing use of FireFox, and the upcoming clients who needs an overseas working solutions, are leading me into finding best practices for cross-browser, same looking web pages design.I’ll target the most widely used (or talked about) browsers at Israel: Internet Explorer 6.0 (IE), and FireFox 1.5 (FF)So here is a little example.Look at the following html page:
<html> <head> <style type=”text/css”> <!– div { width: 100px; height: 100px; background-color: aquamarine; border: 10px black solid; } #div1 { padding: 10px 10px 10px 10px; } #div2 { margin: 10px 10px 10px 10px; } #div3 { border-width: 0px; } –> </style> </head> <body> <div id=”div1”>div1</div> <div id=”div2”>div2</div> <div id=”div3”>div3</div> </body></html>
This page is sopposed to render 3 100100 divs, the first with a 10px padding (distance between border and inner content), and the second with a 10px margin (distance between the border and other elements). The third div has no margin, no padding and no border, and is used for comparing with the first two, showing what a 100100 sized div should look like.Amazingly, IE and FF will render it differently: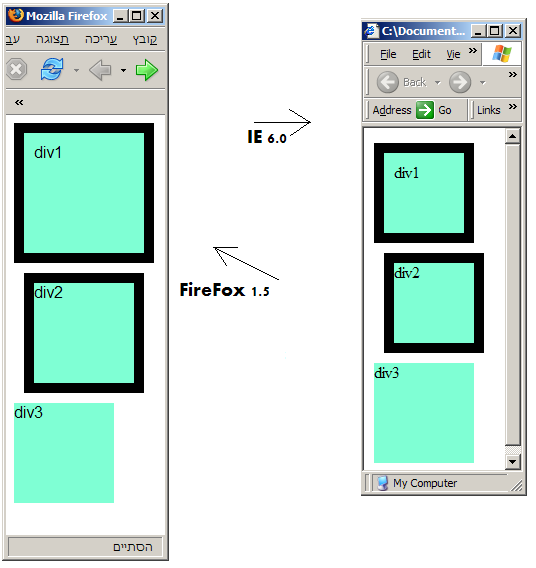 Let’s see what is the difference:The simple 100100 div (div3) was rendered the same on both browsers, except the default font. In the bordered and margined div (div2) things are different:in IE, the border is renderd in the div, so the div with the border is still 100px wide. the inner content is now only 8080in FF, the border is rendered outside of the div, so now the div (including the border) is 120px wide, and the inner content is still 100100the margin magic is done the same. it is rendering a 10px unseen border around the div, in both browsers.Finally: the bordered and padded div (div2).in IE, the padding space is, again (as with the border), renderd in the div, between the border and the inner content, so the div with the border and padding is still 100px wide, and the inner content is now only 6060 !!!in FF, the padding space is rendered outside of the inner content, so now the div (including the border and padding) is 140px wide, and the inner content is still 100*100The IE approach is better for ppl who want to change the border and padding of elements without changing the overall page layout, while the FF approach is better for ppl who thing than the inner content of elements is too important to be covered by borders and padding space …which is better? let’s ask the W3C.The answer is given at http://www.w3.org/TR/CSS21/box.html, and the following diagram of a html element edges is taken from there:
Let’s see what is the difference:The simple 100100 div (div3) was rendered the same on both browsers, except the default font. In the bordered and margined div (div2) things are different:in IE, the border is renderd in the div, so the div with the border is still 100px wide. the inner content is now only 8080in FF, the border is rendered outside of the div, so now the div (including the border) is 120px wide, and the inner content is still 100100the margin magic is done the same. it is rendering a 10px unseen border around the div, in both browsers.Finally: the bordered and padded div (div2).in IE, the padding space is, again (as with the border), renderd in the div, between the border and the inner content, so the div with the border and padding is still 100px wide, and the inner content is now only 6060 !!!in FF, the padding space is rendered outside of the inner content, so now the div (including the border and padding) is 140px wide, and the inner content is still 100*100The IE approach is better for ppl who want to change the border and padding of elements without changing the overall page layout, while the FF approach is better for ppl who thing than the inner content of elements is too important to be covered by borders and padding space …which is better? let’s ask the W3C.The answer is given at http://www.w3.org/TR/CSS21/box.html, and the following diagram of a html element edges is taken from there: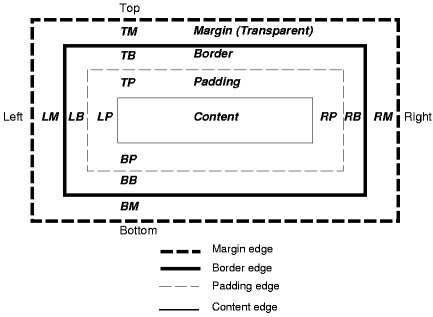 as well as the next quote from just beneath the diagram:
as well as the next quote from just beneath the diagram:
content edge or inner edgeThe content edge surrounds the rectangle given by the width and height of the box …
So according to the W3C, the width and height should refer to inner content of the div (as FF thinks), and not to the border edge (as IE thinks).That leads to the thought that it’s resonable that future releases of IE will do the same as FF do now.But what about today? how do we design in the W3C way, and making the IE understand it the way we want it to?Well, IE can undertand pages as it’s supposed to, if we’d only tell him to.Doctyping the listed page, eiether as HTML4.01 or XHTML1.0, tells IE how to render the page, and then the expected behaviour is achieved.HTML4.01 doctype: <!DOCTYPE HTML PUBLIC “-//W3C//DTD HTML 4.01 Transitional//EN” “http://www.w3.org/TR/html4/loose.dtd”>XHTML1.0 doctype: <!DOCTYPE html PUBLIC “-//W3C//DTD XHTML 1.0 Transitional//EN” “http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd”>For those of us using Visual Studio .NET to generate webforms and webpages, the IDE is generating those doctypes for any new item. VS2003 uses HTML4.01, while VS2005 uses XHTML1.0But there is still a need to do that manually, when you render a page manually, say using a xslt transform from xml resource.I’d recommend using XHTML1.0 transitional as a mininum doctype, and doing your best to make your pages compliant with this standard. It’s making your page look and behaviour much more expected and keeps you from angry clients with a specific browser version. It is also a best practice to program well. Web programming is is the same as any other, and the fact that browsers allow us to make mistakes doesn’t mean that we have to. Imagine VB programmers using only Variant type variables - they’d probably get throwen off the nearest window during code-reviews …It’s true that sometimes we have to make an exception and do some browser specific stuff in order to make things work, and that is exactly a perfect time for some inline remark to explain the reason for doing that. It is also true that ASP.NET 2.0 itself isn’t as XHTML complaiant as it claims, but then again - we’ll do our best to program well and to deliver quality and complaiant code, if only for the sake of doing things right. be good, and remember: Winning is the science of being prepared.Ken