Posts Tagged “javascript”
Follow
Installing older node.js with latest npm on osx
At the time I write this, Heroku support Node 0.4.7, however the latest release is 0.4.8
Installing in the usual way (brew install node) will bring 0.4.8 in, so instead I opted to download the .pkg for 0.4.7
Node.js was installed correctly, however, it came with an old version on npm (the package manager for node.js).
| Searching around for npm installation brought up downloading the sh script and executing it. The snippet is curl http://npmjs.org/install.sh | sh |
For *nix noobs – this mean that the content of the file at http://npmjs.org/install.sh will be pushed as input for sh which is the runner for .sh scripts.
The problem is that the script tries to delete old npm versions, but it fails to do so for lack of permissions. Usually one prefixes with sudo to make this work, however it still did not work for me. What I ended up doing is breaking the process in two – first download the script into a local file (curl http://npmjs.org/install.sh > install.sh) and then sudo sh install.sh
I should be starting a “tips” section on the blog.
Spot the bug … dynamic language slap-on-forehead moment
This is a view template rendering html. When running it, it caused the page to freeze (i.e. the page keeps loading).
<h3>Services</h3>
<% for (var ix=0; ix < view.services.length; ++i) { %>
<% var service = view.services[ix]; %>
<p> <%=service.name %> </p>
<% } %>
Took me a while to grasp it. I tried various things, thought that the templating-engine code was bad, blamed every line of code in the application, until I actually re-read the template code carefully
You see, the indexer is “ix” while the ++ is working on “i”.
Since it is Javascript, no “I do not know what i is” exception was thrown. Instead, the first time it was encountered, JS decided it equals zero, and then the poor thing just kept increasing, probably until it would have overflowed.
In case you have missed it, it was javascript. Not AspView, nor Jsp. I am using a new, super-simple javascript base templating engine, for places where embedding something like AspView would be an overkill, and using NVelocity would be as annoying as using NVelocity.
I hope to have it released as open source soon. Basically it is a simple transformer into simple JS code, and I’m using the supercool Jint libraryfor running it within .NET. I am also planning on making it available for Java at some point using Mozilla Rhino
JavaScript and .NET – meet jint
I’ve been looking for JavaScript scripting possibilities for .NET for quite some time. I always know I could hack an IKVM (java-to-csharp compiler) over Rhino (Java implementation of JavaScript), but it always felt a bit too complex.
I had my hopes on Microsoft to implement a JavaScript over the DLR but the news on the subject where vague at best, and with the latest moves on shutting down support of IronPython and IronRuby, I’d think that IronJS won’t really happen anytime soon. There is a project named IronJS over at github, but it is quite incomplete. (for e.g., the test suite include a single mostly-commented-out file).
Reading one more Rhino/IKVM article on CodeProject this week, I stumbled on a comment pointing to a new JS interpreter implementation for .NET. yup – that’s right. Interpreter. Not a compiler, nor a VM. The project is at http://jint.codeplex.com/.
I Hg cloned the repo, ran MsBuild.exe on the Jint.sln file, and referenced output binaries (only two dll files - jint’s and antlr’s), and voila.
the following stupid code, showing executing JS code (see the regex syntax in script1), executing .NET code from JS script (the DateTime class), and passing a .NET object as parameter to the script:
class Person
{
public string Name;
}
static void Main(string[] args)
{
var script1 = @"return 'hello'.replace(/l{2}/gi, 'LL');";
var script2 = @"var d = new System.DateTime(2010,3,1);
return d.Day;";
var script3 = @"return 'hello ' + p.Name;";
var jint = new Jint.JintEngine();
var result1 = jint.Run(script1);
Console.WriteLine(result1);
var result2 = jint.Run(script2);
Console.WriteLine(result2);
var p = new Person { Name = "Ken" };
jint.SetParameter("p", p);
var result3 = jint.Run(script3);
Console.WriteLine(result3);
}
The output is:
heLLo
1
hello Ken
so what the whole fuss is about?
think about a view engine that can execute in the Server for generating initial http response, and then executing the same templates on the client-side. Not only that, it should be possible to share templates between Java and .NET servers in a heterogeneous environment
I know that Spark view engine support both server and client side execution, but I remember hearing from the leaders of Spark that it was never a goal, and I also do not like the syntax of Spark anyway (brings back bad memories from nant)
It also has a few more appealing features. For one, it does not generate bytecode, so you can hot-swap scripts without leaking memory.
I’ll be playing with this some more should time allow.
The right tool for the job, XSS edition
It is not very uncommon to see pages that include a “returnUrl” parameter, usually within authentication flows. At times, the browser will run some script (like a call to an analytics service) and then another script issuing a redirect (through setting location.href etc.)
There are also other cases where UGC can find its way into JavaScript blocks. People might want to have their script do fancy stuff with the page’s data.
var url = '<%=viewData.returnUrl%>';
or
var commenterName = '<%=viewData.newComment.authorName%>';
for e.g.
Now for the “stating the obvious”:
Just like any other UGC, this type of content must be sanitized to prevent XSS attacks.
Not to long ago I was called to do a security inspection on a web application’s codebase. During which, some very few XSS holes were detected using JavaScript injection. This was quite surprising to me, as I knew that all content injected into JavaScript was being sanitized by the team.
Digging further I found out that they did call a sanitize function on UGC, just not the correct function. What they did was to run a JSON formatter over the UGC string, a thing that was solving JS errors occurring from string quoting problems, but it did not eliminate malicious scripts.
The weird thing was that the team was already using the AntiXss library (which is a very aggressive, white list based input sanitation library for .NET), for html fragments. The library also have a JavaScript Encode function. Switching the sanitation function of the team from calling the JSON library to calling the AntiXss library fixed the problem for good.
e.g. code to demonstrate the difference between the methods:
static void Main()
{
var ugc = "';alert('xss');'";
Render(JsonConvert.SerializeObject(ugc));
Render(AntiXss.JavaScriptEncode(ugc));
}
static void Render(string encoded)
{
Console.WriteLine("var returnUrl = '"+encoded+"';");
}The output from the above snippet is:
var returnUrl = '"';alert('xss');'"';
var returnUrl = ''\x27\x3balert\x28\x27xss\x27\x29\x3b\x27'';
There are a couple of things to learn from that story:
- When you encounter a problem, look around for common solutions. for e.g., every language that is being used for web development today has a library that takes care of XSS, so use it instead of coming up with a partial solution using the wrong library, or even worse –try to re-invent the way of doing that. You are probably not in the business of Anti XSS, so don’t spend time on solving the problem.
- Know your toolbox. If you are using a tool, be aware of its capabilities (and shortages). Exploring the AntiXss library a little bit would have shown the team that there is a perfectly good solution for their problem.
Newlines in textarea are treated differently on different browsers
And guess who is the craziest one.
scenario
Client side validation is good right? so you have this field of User Generated Content, which is exposed via a textarea element on your page. For e.g. – comment on blog post.
Now you have a limit of N characters on the field, maybe enforced within a DB constraint or whatever.
First attempt:
function validateMaxLength(elmId) {
var element = document.getElementById(elmId);
var elementContent = element.value;
var elementContentLength = elementContent.length;
return elementContentLength <= N;
}or something like that.
BUT
think again.
Assuming the element’s content was something like
the element contains at least
one newline
how would you count newlines? would you count two characters per newline (for \r\n)? or only one?
When I faced that problem I checked how the browser is counting the newlines. I ran a quick test as saw that it counts newlines as a single character. Since the content was needed to be presented within a web element anyway, and newlines were to be changed to <br/> tags at render time anyway, I decided to have the server code make sure that incoming strings will use only \n for newlines, then validate the length, then store in the DB.
Now the client side JS matched the server criteria.
Case closed.
Or was it?
QA kicks in
After a little while I got a bug opened by the QA team about inconsistency between client and server validation regarding lengths of string.
Checked it, and was about to close the bug with a “works for me” message, but then it hit me.
You have to be so special
On IE, newlines are \r\n, so it reports too many characters, and the validation might fails wrongfully. Since I mostly use Chrome for day-to-day, and since I did not suspect that to be a cross-browser issue, I never tested it on IE during development.
Solution
Good old string.replace
elementContent = elementContent.replace(/\r\n/g,'\n');Ken,
the cross-browserer
Error – the current website’s developer is a complete moron
How lame can you get?
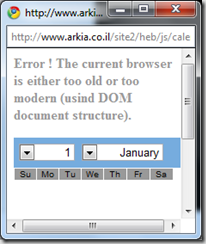
It is even misspelled.
The funniestsaddest thing is the source of this page:
<script language="JavaScript">
if (document.all) {
document.writeln(...);}
else {
document.writeln("<p><font color=\"#999999\"><b>Error ! The current browser is either too old or too modern (usind DOM document structure).</b></font></p>");}
</script>
So many bad practices in a such a small snippet. And the stuff in the (…) part was too painful to paste.
Javascript and the extended Array prototype
I do quite a bit of javascript stuff lately, and I wanted to enjoy the easier syntax of array methods such as forEach, find etc.
As the current project is not using prototype.js, but rather a different js stack (jquery, various jquery plugins, EJS, and a bit more) I did not have the extended Array stuff that comes with prototype.js
But before I ran off to add the needed methods to Array’s prototype, I had an annoying voice in the back of my head, whispering “extending Array’s prototype is evil, extending Array’s prototype is evil”, so I looked at alternatives.
Alternative 1 – subclassing Array. I went ahead to implement a MyArray (or Array2) type of solution.
using one method of JS subclassing I thought of
var MyArray = function() {
};
MyArray.prototype = new Array;
MyArray.prototype.forEach = function(action) {
for (var i = 0, l=this.length; i < l, ++i)
action(this[i]);
};
...
the problem with that approach is that IE does not like Array subclassing, thus the .length property becomes unreliable, rendering the whole idea of subclassing Array useless.
Alternative 2 – using a different object alltogether It would work, however things like
if (anArrayInstance instanceof Array)
will naturally break.
Alternative 3 – extend any ‘interesting’ instances
function extendArray(arr) {
if (arr.__wasExtended) return;
arr.forEach = function(action) {
for (var i = 0, l=this.length; i < l, ++i)
action(this[i]);
};
arr.__wasExtended = true;
}
which is wrong as any instance will get a copy of all the functions, so too much memory will be used for non-core functionality
Alternative 4 – use the separated scoped Array trick just read http://dean.edwards.name/weblog/2006/11/hooray/
the idea is to use an Array object from a separate iframe, thus enjoy the Array (instanceof), but not interfere with existing Array object on the main window
On top of all that. all three alternatives are problematic, as a regular
var a = [];
will not be extended. which is not such a big problem if you’re disciplined enough, but it’s terribly annoying to need to extend every array you want. think about JSON data you get from a service. you’d first have to iterate over the object graph and extend all of the arrays. yuck.
Now, do you remember that annoying voice from the back of my head? I decided to stand up to him !
Why actually not extend the Array prototype and be done with it?
It will solve the “instanceof” problem, it will solve the need to apply the functions manually on all arrays (as any [] will natively have the new functions), and it wouldn’t cost much memory as it will only be added to the single prototype of all array instances.
The usual reason for not wanting to do so, is that it would break the associative array ‘feature’ of javascript, and you won’t be able to
for (var i in myArray)
anymore.
You know what? that reason is a total bullshit.
Why? cuz there’s not such thing as an associative array in javascript !
If anything, the Object object is similar enough. However the Array object should be used with 0-based integer index, just like any native java/c#/c/whatever array.
Removing that ‘problem’ from the equation, and we can resort back to stuff like
Array.prototype.numSort = function() {
this.sort(function(a, b) { return a - b; });
return this;
};
Array.prototype.forEach = function(action, index) {
for (var i = 0, l = this.length; i < l; ++i)
action(this[i], index);
};
Array.prototype.find = function(func) {
for (var i = 0, l = this.length; i < l; ++i) {
var item = this[i];
if (func(item))
return item;
}
return null;
};
Array.prototype.where = function(func) {
var found = [];
for (var i = 0, l = this.length; i < l; ++i) {
var item = this[i];
if (func(item))
found.push(item);
}
return found;
};
You just have to love dynamic languages :)
Extracting text from a DOM element
I’ve just been asked the following question by a friend:
in javascript - how do i get the text of an html-element, which doesn’t include text of all the children? firefox only
Every html DOM element has a collection of direct children, called childNodes. Each node has a type, and text nodes (those are text portions that are part of an element’s inner content) have ‘3’ for their type.
So, the following code is the solution:
function extractFirstLevelTextFrom(elm) {
var text = '';
for (var i =0; i < elm.childNodes.length; ++i) {
if (elm.childNodes[i].nodeType==3)
text += elm.childNodes[i].nodeValue;
}
return text;
}
[not] storing data in DOM elements - jQuery.data function
At time you’d want to store data, related to a DOM element.
storing it directly into the element (either by elm.someArbitraryName = value, or with setAttribute) is wacky. Some browsers might not like you using non standard attributes, so you start using things like ‘alt’ and ‘rel’. Then again, these things has meaning, and storing arbitrary data is … well, uncool to say the least.
jQuery.data() to the rescue. As jQuery objects are wrappers that HasA DOM elements, and not the DOM elements themselves (as in prototype), storing data on them is like storing data on POJSO (Plain Old JavaScript Objects), and the data() functions allows for an easy way of doing that.
Read on that (and of a few other jQuery tips) at http://marcgrabanski.com/article/5-tips-for-better-jquery-code
Single and looking
explanation (before the wife kills me): I have some free time in the coming months, so I’m looking for interesting consulting gigs.
So, if you’re in a company / dev team, and looking for some help with Castle (Windsor, MonoRail), NHibernate, or general information system design and architecture advices or training, setting up build and test environments, or any other of the things I rant about in this blog, then I’m your guy.
I also do web-client ninja work, dancing the crazy css/html/javascript tango (jQuery: yes, Ms-Ajax: no)
I currently live in Israel, but I’m fine with going abroad for short terms if you’re an off-shore client.
you can contact me at “ken@kenegozi.com”
int.Parse != parseInt
Serving as a mental note, and as a service to dear readers who hadn’t been bitten by this yet.
javascript’s parseInt method is not the same as .NET’s int.Parse.
there’s this ‘radix’ argument which is meant to tell the parseInt method whether we want to treat the string we parse as binary, octal, decimal, hexadecimal or whatever.
Now the naive programmer (a.k.a. myself) would think that the default is always base 10, so parseInt(x) === parseInt(x, 10) for every x.
Apparently parseInt tries to outsmart us, and it’s actually guessing the radix if not set. so if x begins with 0x, it would guess hexadecimal, and if x begins with 0 it would guess it’s octal.
so, parseInt(‘010’) === parseInt(‘010’, 8) === 8
ok, I can live with that maybe.
however it would also ‘guess’ that 09 is octal (even though 9 is not an octal digit !) thus parseInt(‘09’) === 0
I found this by chance, when a Date.parse method I have was parsing "09/07/2008" into a date-info object with day==0, causing it to fall back into today’s date
So, the lessons we’ve learned today:
- javascript is not c#
- always set the radix when using parseInt - parseInt(x, 10)
- don’t let your cat spill a glass of soda on your desk as it would ruin your earphones, and unless the laptop was on an elevated stand it would have ruin it also
ASP.NET Ajax UpdatePanel Challenge
Actually, it’s not much of a challenge, but it is a catchy title.
Or is it?
Anyway, that’s the details:
I’d kindly ask all of you ASP.NET Ajax wiz guys (and gals), to supply me with a simple UpdatePanel thing.
What should it do?
I want to have a webpage, based onthis template, that on dropdown change, will go to the server with the selected value in the dropdown, and update the data (table) with some crap, based on the sent value.
You can leave the actual data retrieval to a simple method returning an array of string array, or you can go and implement a CodeSmith/DAAB/Whatever based supercool data access code. I would ignore it anyway. I want the Ajax stuff.
Now, to the why.
I am doing that MonoRail presentation at Microsoft’s Israel IVCUG (Israel Visual C(#/++) User Group) next week. I might be showing some demos, and I want to be fare when I show a comparison to WebForms stuff, and not come up with a crappy code and say “ha ha”, but show something that one of you, my-dear-readers-who-actually-uses-asp-net-ajax-for-living, wrote, and is considered a good example.
Also, I’m lazy. Seriously. Creating a presentation takes a LOT of time and effort, and I do not have much of the first, and rather avoid much of the later.
So, please do send me that code, to my-first-name at that-blog’s-hostname.
thanks.
My first CodeProject article is up
I’ve posted an article to CodeProject about building my Google Ajax Search EnabledHomepage.
So, go there, read it, comment it, vote for it, tell your friends about it, print it and glue it to your forehead, whatever you think is appropriate.
Unless you didn’t like it. In that case, you shouldn’t do anything. why bother ? :)
Google AJAX Search API and My New Homepage
I have loaded a new homepage, and used a little of the Google AJAX Search API to make it interesting. Actually, I’m using it now as my browser’s default homepage, instead of google.com
Not only that, but I have documented the process of making it, and have sent it to codeproject, to be published, as my first contribution there, in hope for more to come.
So, please leave your impressions, eiether here or in the codeproject article (I’ll post the addresss once it will be up).