Posts Tagged “azure”
Follow
Excel and Mobile Services take 2
I have updated the code from my recent post, Using Excel to edit Azure Mobile Service table data, to support Insert and Update.
In order to delete a record, you’d need to have a cell from that record selected, then click on the Delete icon on the Add-Ins ribbon menu. The only requirement is to actually have a value in the first cell of that line.
In order to Insert a record, you’d need to set the fields, and keep the id empty, then click on the Add (plus) icon on the Add-Ins ribbon menu when a cell in that new record’s row is selected.
Using Excel to edit Azure Mobile Service table data
When building apps for Mobile Services, you often need to manipulate the data stored in your table from an admin point of view.
The management portal of Azure does let you browse your data, but not edit it.
A few days back, Amit showed on his blog a way to create a simple data manager as a Windows 8 Application, using the official SDK.
I however like the UI of Excel for data editing, so I wanted to create a simple editor that taps to Excel mechanisms, and uses the unofficial SDK to communicate with the mobile service.
The results can be seen in the following recording (you’d want to watch it in HD):
How?
First, I created an Excel AddIn project in VS2012. Then I grabbed the latest SDK file from github, and added it to the project. Lastly, I changed the AddIn code to look like that gist (you’d need to set your app url and key), and ran the project.
Current limitations:
- I am a very poor VSTO developer. There are probably million ways to do the Excel bits better. I’d appreciate constructive comments on the gist.
- The current implementation does not support row inserts and deletes. UPDATE [9/11/2012] Insert and Delete works now!
- Dates will lose millisecond precision.
- And it will not work with “Authenticated only” tables.I will be adding a support for the Admin Key that Amit showed on his blog to solve this
Using Azure Mobile Services with Windows Phone
Windows 8 app building is great With the new awesomeness that is Azure Mobile Services, building a cloud-connected application became much easier.
Now you just probably say “I wish it would have worked with other client platforms as well as Windows 8”
Guess what? HTTP The service is actually talking to the SDK via HTTP, and the Windows 8 SDK that is published along is a (very rich, awesomely done) wrapper around that HTTP API. Given that, I jumped ahead and implemented a (very poor, awfully done) SDKs for Windows Phone. Disclaimer #1 What you see here in this post and other related ones is 99.999% guaranteed to fail for you. It is a hack job that I put together in a few late-night hours, and it is *not endorsed by the Mobile Services team. It is likely that if and when we do come up with an official WP SDK, it would be looking different. Very different. Even the HTTP api that I’m using here is likely to change by the time the service gets out of Preview mode. codez You can peak at some of the usages for the API in the following gist:
In follow up posts, I will cover the API more, and I will also be adding xml comments to the SDK to make it easier to use. How to get it? Head over to https://github.com/kenegozi/azure-mobile-csharp-sdk.you could either clone the repo, or just navigate to /src/MobileServiceClient.cs , click on the ‘Raw’ button and save it in your project.You’d need to have the latest Newtonsoft’s Json.NET referenced as well (if you don’t have it already).A NuGet based delivery is in the works.
- I am also working on a similar SDK for Android. I’ll get to work on a iOS one as well once I get around to install Mountain Lion on my MBP Disclaimer #2 Although I do work on the Mobile Services feature in Azure, the opinions, code, and sub-par grammar I voice on this blog is completely my own, and does not reflect my employer’s opinions, code, or grammar. This is not where you will get any official Azure announcements, you’d need to check out other places (I’d suggest http://WindowsAzure.com and Scott Guthrie’s blog as good starting points)
From MongoDB to Azure Storage
My blog has been running happily for some time on a MongoDB storage. It used to be hosted on a VM in a really awesome company, where I had both the application and the DB sharing a 2GB VPS, and it worked pretty well.
At some point I moved the app to AppHarbor (which runs in AWS) and I moved the data to MongoLab (which is also on AWS). Both are really great services.
Before it was running on MongoDB, it used to be running on RDBMS (via NHibernate OR/M) and I remember the exercise of translating the Data Access calls from RDMBS to a Document store as fun. Sure, a blog is a very simplistic specimen but even at that level you get to think about modeling approaches (would comments go on separate collection or as subdocuments? how to deal with comment-count? and what about tag clouds? what about pending comments that are suspected to be spam?)
I am now going to repeat that exercise with Azure Storage.
The interesting data API requirements are:
- Add Comment to Post – atomically adds a comment to a post, and updates the post’s CommentsCount field.
- View-By-Tag (e.g. all posts tagged with ‘design’, order by publish-date DESC)
- view latest N posts (for atom feed, and for the homepage)
- view Monthly archive (e.g. all posts from July 2012)
- Get a single post by its permalink (for a post’s page)
- Tag Cloud – get posts count per tag
- Archive summary – how many posts were published on each month?
- Get total comments count (overall across all posts)
- Store images, while using a hash of the content to generate etags for controlling duplications.
Given the rich featureset of MongoDB, I was able to use secondary indexes, sub-documents, atomic document updates and (for 4, 6 and 8) simple mapReduce calls. The only de-normalization was done with CommentsCount field on post, which is atomically updated every time a comment is added or removed from the post, so the system stayed fully consistent all the time. The queries that required mapReduce (which could get pricy on larger data-sets, and annoying even on small ones) where actually prone to aggressive caching, so no big pain there.
I will be exploring (in upcoming posts, its 2am now and the baby just woke up) what it takes to get the same spec implemented using Azure Storage options – mostly Table Storage and Blog Storage.*
- yeah there is SQL Azure which is full fledged RDBMS, which can easily sport all of the requirements, but where’s the fun in that?
Phantom feed entries with Google Reader–problem hopefully solved
I have had a few glitches recently with my blog’s feed. From time to time, the latest 20 items would re-appear as new, unread items in Google Reader.
It annoyed me, annoyed a few of my readers – some contacted personally, and eventually this happened:
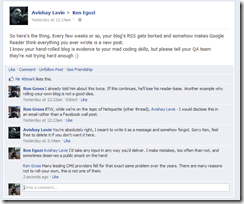
I first suspected that the Updated or Created timestamp fields might be wrong, but looking at both the feed generated by the blog, and the feed as it is being served by feedburner showed me that these fields did not magically change.
I did however find the problem.
My feed is in ATOM 1.0 format, and each entry has an <id> field.
The id I am putting there is the permalink to the post, and here comes the interesting part – I was taking the domain part of the permalink from the current request’s url. I was doing that because I was, how to put it, short sighted.
Anyway as soon as the blog engine moved from my own, fully controlled VM hosted somewhere, to more dynamic environments (AppHarbor at first, now Azure WebRole), behind request routers, load balancers and such, the request that actually got to the blog engine had its domain name changed, and apparently not in a 100% consistent way. The custom cname that was used was changing every now and then (every few or more weeks) and then Google Reader would pick up the changed <id> and even though the title, timestamps and content of the posts remained, the changed <id> made it believe it is a new post.
I now hardcoded the domain part, and all is (hopefully) well.
If not – you can always bash me on facebook :)
The new Web Sites feature in Windows Azure–A story in pictures
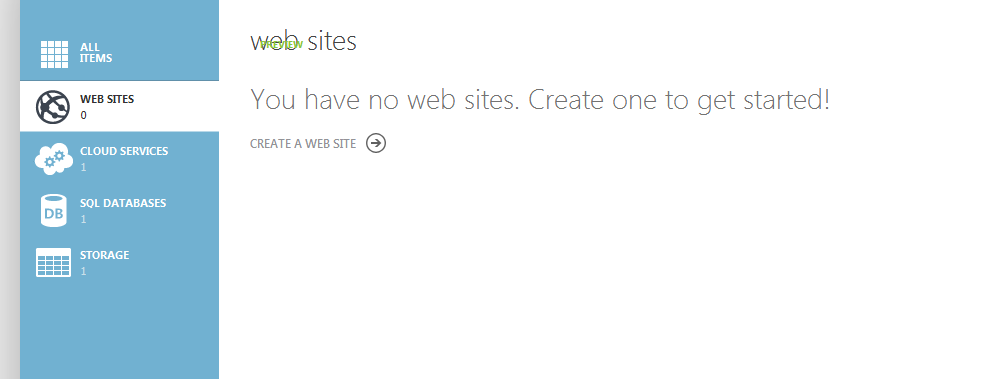
Hello portal:
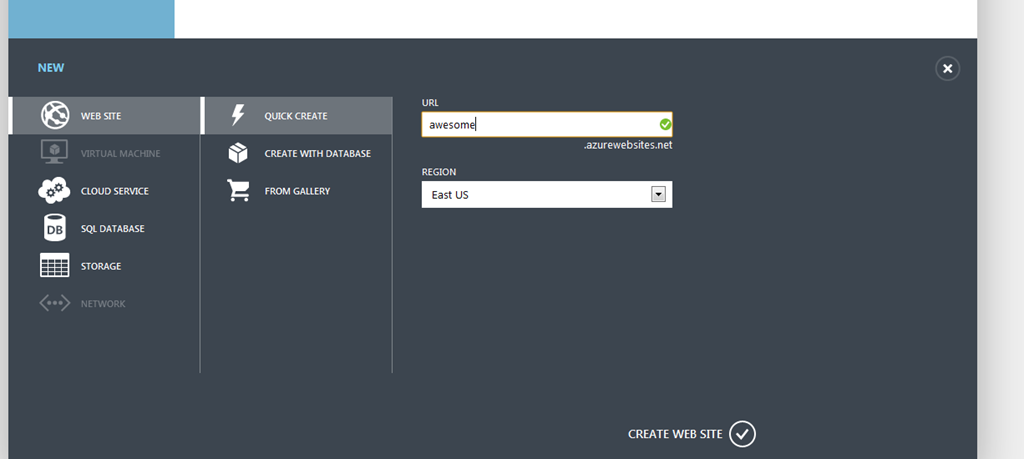
Create new site:
Hi there!

Can do some stuff, maybe later
What’s inside? first-time wizard

Setup git (I’ll spare you the username/password)

The best ide ever – echo
git it

browse it
monitor it

scale it
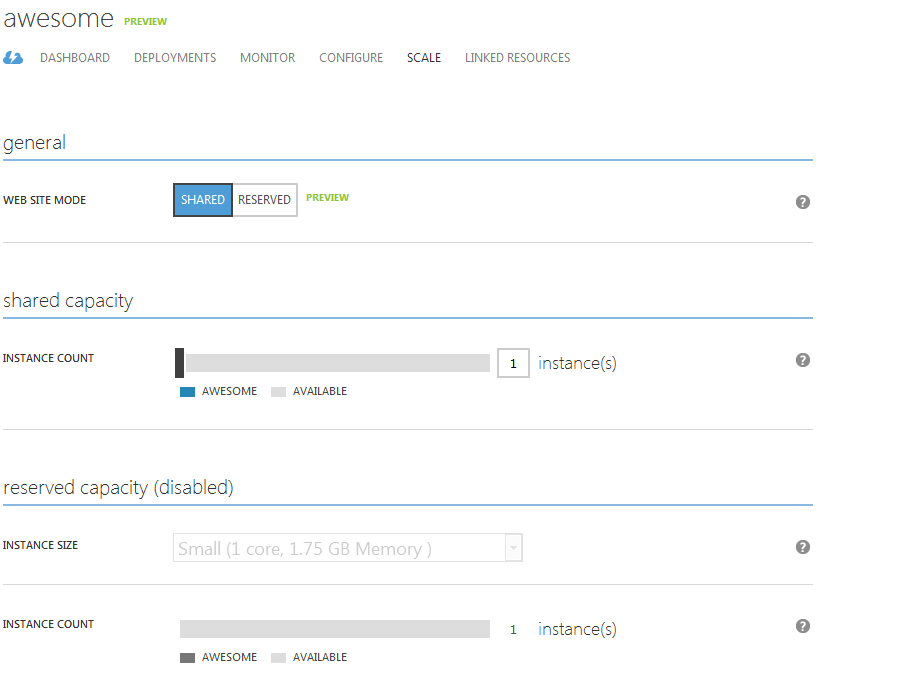
Have you noticed the “reserved” option? you could actually scale it to a dedicated VM (or a few), using the exact same simple deployment model.
And of course it’s not only for text files. you could run PHP, node.js, as well as the more expected ASP.NET stack, on top of this.
want it
The Web Sites feature is still in preview mode. To start using Preview Features like Virtual Network and Web Sites, request access on the ‘Preview Features’ page under the ‘account’ tab, after you log into your Windows Azure account. Don’t have an account? Sign-up for a free trial here