Posts Tagged “blog-engine”
Follow
Using gists in your blog? Embed them into your feed
I love using github gists for code snippets on my blog. It has many pros, especially how easy it becomes for people to comment and suggest improvements, via the github mechanisms we all love.
There are however two drawbacks that people commonly refer to with regards to using gists that way:
- Since the content of the code is no longer part of the post, it is not being indexed by search engines, and
- Since the content of the code is not part of the post, and since the embedding mechanism is JS based, people who consume the blog via the feed and use feed aggregators that does not run javascript (most of them don’t), will not get the contents.
My answer to the first one is simple. I don’t really care. Not that I do not care about SEO, just that I do not need to have my post indexed and tagged under a bunch of irrelevant reserved words and common code. If the snippet is about using an interesting component ABC, I will mention that said ABC in the post content outside of the snippet, problem solved.
The latter is more interesting. I used to manually add a link to the gist page whenever embedding one, but it is not a very fun thing to do.
So, in order to overcome this, I wrote a small code snippet (yey) that upon saving a post (or updating it), will look for gists embeds, grab the gist source from github, stick in into the post as a “ContentForFeed” and serve with a link to the gist page, just for the fun of it.
And the code for it (it’s a hacky c#, but easily translatable to other languages, and/or to a cleaner form)
Have fun reading snippets
From MongoDB to Azure Storage
My blog has been running happily for some time on a MongoDB storage. It used to be hosted on a VM in a really awesome company, where I had both the application and the DB sharing a 2GB VPS, and it worked pretty well.
At some point I moved the app to AppHarbor (which runs in AWS) and I moved the data to MongoLab (which is also on AWS). Both are really great services.
Before it was running on MongoDB, it used to be running on RDBMS (via NHibernate OR/M) and I remember the exercise of translating the Data Access calls from RDMBS to a Document store as fun. Sure, a blog is a very simplistic specimen but even at that level you get to think about modeling approaches (would comments go on separate collection or as subdocuments? how to deal with comment-count? and what about tag clouds? what about pending comments that are suspected to be spam?)
I am now going to repeat that exercise with Azure Storage.
The interesting data API requirements are:
- Add Comment to Post – atomically adds a comment to a post, and updates the post’s CommentsCount field.
- View-By-Tag (e.g. all posts tagged with ‘design’, order by publish-date DESC)
- view latest N posts (for atom feed, and for the homepage)
- view Monthly archive (e.g. all posts from July 2012)
- Get a single post by its permalink (for a post’s page)
- Tag Cloud – get posts count per tag
- Archive summary – how many posts were published on each month?
- Get total comments count (overall across all posts)
- Store images, while using a hash of the content to generate etags for controlling duplications.
Given the rich featureset of MongoDB, I was able to use secondary indexes, sub-documents, atomic document updates and (for 4, 6 and 8) simple mapReduce calls. The only de-normalization was done with CommentsCount field on post, which is atomically updated every time a comment is added or removed from the post, so the system stayed fully consistent all the time. The queries that required mapReduce (which could get pricy on larger data-sets, and annoying even on small ones) where actually prone to aggressive caching, so no big pain there.
I will be exploring (in upcoming posts, its 2am now and the baby just woke up) what it takes to get the same spec implemented using Azure Storage options – mostly Table Storage and Blog Storage.*
- yeah there is SQL Azure which is full fledged RDBMS, which can easily sport all of the requirements, but where’s the fun in that?
Phantom feed entries with Google Reader–problem hopefully solved
I have had a few glitches recently with my blog’s feed. From time to time, the latest 20 items would re-appear as new, unread items in Google Reader.
It annoyed me, annoyed a few of my readers – some contacted personally, and eventually this happened:
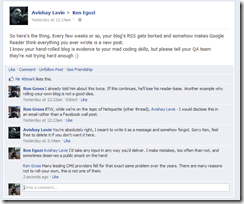
I first suspected that the Updated or Created timestamp fields might be wrong, but looking at both the feed generated by the blog, and the feed as it is being served by feedburner showed me that these fields did not magically change.
I did however find the problem.
My feed is in ATOM 1.0 format, and each entry has an <id> field.
The id I am putting there is the permalink to the post, and here comes the interesting part – I was taking the domain part of the permalink from the current request’s url. I was doing that because I was, how to put it, short sighted.
Anyway as soon as the blog engine moved from my own, fully controlled VM hosted somewhere, to more dynamic environments (AppHarbor at first, now Azure WebRole), behind request routers, load balancers and such, the request that actually got to the blog engine had its domain name changed, and apparently not in a 100% consistent way. The custom cname that was used was changing every now and then (every few or more weeks) and then Google Reader would pick up the changed <id> and even though the title, timestamps and content of the posts remained, the changed <id> made it believe it is a new post.
I now hardcoded the domain part, and all is (hopefully) well.
If not – you can always bash me on facebook :)
Re-blog
My blog has moved to AppHarbor, and while doing that I also changed the engine for a completely custom thing (running on custom-y stuff like WebOnDiet and NTemplate), to a wee bit more conventional codebase based on MVC3 and Razor, with lots of nuget packages replacing custom code that I wrote myself.
The packages file now contains AntiXSS, AttributeRouting, Castle.Core (for my good pal DictionaryAdapterFactory), elmah, MarkdownSharp, mongocsharpdriver, XmlRpcMvc and XmlRpcMvc.MetaWeblog (awesome!)
BTW, expect a post on using the DictionaryAdapterFactory to make handling Controller=>View data transport truly awesome.
What’s missing here? IoC !
yeah I did not bother with that now. I have my tiny 15LOC thing and this blog does not need anything of this sort.
Some things might still break. Files I used to host for downloading would probably won’t work now. I will fix that soon I hope, time permitting.
note to self – reshuffle the tags here on the blog. I need to re-tag may entries. Maybe I’ll let site visitors suggest tags?
Google Reader bug leading to a glitch in my feed
I have recently change the blog engine, and as part of that move, the permalinks for posts changed a bit (removed the .aspx suffix, and also got rid of the www. prefix)
So, the atom feed now lists a different <id> tag for each entry (post).
Google Reader cache data on posts based on the id tag, therefore subscribers to my blog who are using Google Reader will probably see 20 new messages.
The real glitch though is a bug in Google Reader. As far as reader is concerned, the <updated> and <created> tags does not mean a lot. It uses the time at which it discovered the entry as its date, for display (and sorting). This is arguable, and their argue is solid - since feeds are (at least historically) primarily made for news, they wanted to disallow publishers to twist scoop times.
So, I can understand why all my last 20 entries re-appear with the same date.
The annoying part is that Reader chooses a weird way to sort them. It could have at least use the publish date as a secondary sort order.
So, sorry for the glitch, and for those of you coming to my site, sorry for the poor UI design - a full redesign is in the make and will be pushed as soon as I can.
Please update your feed source
If you’re reading my blog through a feed, please update your link to http://feeds.feedburner.com/kenegoziif you hadn’t yet, theweb server would appreciate it.
New Look
sneak peek (for those who read this through a feed reader):
cool huh?
Comments Are Back
So you can tell me what you think on the new design, or any other thing (like what you think on the new changes to AspView, how you like working with the Castle stack,how great AspView is, how good looking I am, and any other kind of constructive criticism).
Comments are temporarily off
Sorry.
I need to do that, at least for a few days.
If you want to leave a message, mail me:
blogat the-domain-name-of-this-blog (without the www part, of course …)
Horrible spam
I haven’t monitored the blog’s comments for only a week, and now I’ve had to delete 988 spam messages.
I guess I’m going to re-do the comment mechanism really soon.
Feeds Should Be Back On Now
It is possible though that your reader might want to update last 20 posts.
Next step - some look’n’feel improvements.
Upgrading Blog's Engine - There Be Dragons
I’m upgrading the blog now, so it might be a bit quirky for a bit. Please be patient.
Also,if you are a I-comment-on-the-blog-and-tick-remember-me kind of guy, then pleasecheck your details next time you comment, and then re-tick the remember-me thing, as there was a bug in the cookie storing method.
I've Ruined the Syndication
Did an upgrade, did it bad, Syndication is down (no atom feed).
fixing it soon.
MonoRail / AspView Talk in IVCUG
I did that MonoRail / AspView talk yesterday at August’s IVCUG (that’s Israeli Visual C#/++ User Group) at Microsoft offices in Raanana, Israel.
I was a great experience for me, and I thank all of you who came in, asked questions, left some change in my hat (damn, I forgot the hat), and (hopefully) had a great time.
The presentation will be uploaded here soon, so will the demo code, and the promised zip with AspView executables for castle build 472 (revision 4016) + stub web.config. It’s just that I need to actually WORK today since the last days was more “prepare to presentation” that “work for a living” kinda days.
So, tune in. It would be by here this weekend.
Meanwhile you can go over aspview source code (there’s AspViewTestSite that demonstrate many of MonoRail and AspView features. It’s quite old and when I wrote it I was quite a MonoRail newbie, so stuff there are not necessarily best-practice quality, but you can grasp how to use subviews, viewcomponents, viewfilters, etc very easily).
http://svn.castleproject.org:8080/svn/castlecontrib/viewengines/aspview/trunk/
You can also look over my blog engine’s sources that I have presented yesterday. It’s at:
http://kenegozi-weblog.googlecode.com/svn/
The code shown was from going-ddd branch.
bad name btw, as the model is too simple for DDD, and I also violate it from time to time … (Repository<Comment> …)
Redirecting syndication link from dasBlog's one to the new one
TodayI was informed by Dror that although I managed to redirect all requests to html/aspx url’s on my blog (the ones that dagBlog was using) to the new pemalink format, I forgot to do the same for the old syndication link.
So that link was http://kenegozi.com/blog/SyndicationService.asmx/GetRssand now it’s http://kenegozi.com/Blog/Syndication/Atom.aspx
I could’ve used the monorai redirection module that is already in use on my blog, but I chose to do it differently, with a dedicated handler, just to show how easy it is do to such stuff, even without a full blown redirection engine.
So, I’ve added this:
publicclassSyndicationRedirectionHandler : IHttpHandler
{
#region IHttpHandler Members
publicbool IsReusable
{
get { returntrue;}
}
publicvoid ProcessRequest(HttpContext context)
{
context.Response.StatusCode = 301;
context.Response.Redirect("http://kenegozi.com/Blog/Syndication/Atom.aspx");
}
#endregion
}
and that line into web.config:
<addverb=”*“path=”SyndicationService.asmx”type=”KenEgozi.Com.Weblog.SyndicationRedirectionHandler, KenEgozi.Com.Weblog”/>
Voila.
Default value for value type parameter in AspView does not work
Today we tried to have this in a view’s parameters section:
<%
int id = default(int);
%>
It won’t work.
Internally, AspView looks for a parameter (in the PropertyBag, Flash, Form, QueryString etc.) with the name “id”.
Now if it is not found, it should set to “default(int)”. The problem is duw to a bug in AspViewBase (which is the base class for all views) that sets a null value if the property is not found, thus failing the cast to value type (you cannot (int)null).
I’ll add a test, fix the bug, and commit it, hopefully by this weekend.
Meanwhile, we “solved” the problem by using:
<%
object id = default(int);
%>
Full blog comments feed
The newest addition to the blog engine.
From the subversion commit comment:
Some refactoring to avoid code duplicationAdded support for CommentsAtom - a feed with all of the comments in a blog, used for tracking purposes by the blog writer
Now you can access http://the_blog_url/Syndication/CommentsAtom.aspx and get a feed of all the comments.
Useful as a tool for the blog writer, as it enables tracking of comments all overthe blog
as usual - sources are here.
New feature to the blog - a blogroll
just added a blogroll.
To the DB, to the Domain, to the controller and to the view.
Took me (all in all) 30 minutes, including all the coding, CSS-ing, uploading to the webserver, setting up the DB table on the hosted server, adding a few entries, clearing the browser’s cache, and viewing it.
ah, and committing changes to Google code.
All of that was made in the Budapest Airport cafeteria, while waiting for my flight home (was a great trip. Photos, though not many of them, will be posted later on).
Rest assure that the DB access code is tested, and that the calls to the DB and to the cached data from the Controller and View are all typed.
I’d like to thank NHibernate, Castle and AspView (hey - that’s me !), who made this possible.
I bet Ayende would have done it in 20 …
A new feature on my blog: Comments feed
Just added.
Commited to the repository, too (hosted at google code).
Look for the link on each post’s footer.
Things my blog is missing
Since this blog is running on an engine that I wrote (available on Google code site, here), it lack some features that more mature blog engines already have. (the other engines lacks the combined power of ActiveRecord/MonoRail/AspView …)
So, that’s currently my list:
-
Blogroll, for obvious reasons.
-
Email alert for me when anyone posts a comment for one of my posts.
-
Comments feed (via ATOM).
UPDATE - Done
-
Email subscriptions for new posts, or new comments on specific posts.
-
I have a problem with the font. I should fix the CSS but the Internet connection here (I’m at a Budapest hotel) is quite poor. Will be fixed next week.
UPDATE - Done
Any other suggestions?
note that I do not intent on implementing Pingbacks and Trackbacks, since those were littering my blog in the past.
My blog is running on ActiveRecord-MonoRail-AspView
So long dasBlog. It was great to have you, but it’s time to move on.
After a lot of work, I am proud to announce that my blog is running on MonoRail, using AspView for the views, and ActiveRecord to do DB stuff.
Not too fancy codewise, since I have very little spare time.
Most of the time spent on the blog upgrade process was on:
-
Exporting the data from the “old” blog, and
-
making a decent markup and design for the new one.
oh. and 3. letting WindowsLiveWriter do the edits, since I wasn’t in the mood to create a backoffice.
I’ll blog more about the process, and I’ll make the source available.
Please leave your comments here about the overall look’n’feel. There must be tons of bugs and I want your feedback.