Posts Tagged “tools”
Follow
Using gists in your blog? Embed them into your feed
I love using github gists for code snippets on my blog. It has many pros, especially how easy it becomes for people to comment and suggest improvements, via the github mechanisms we all love.
There are however two drawbacks that people commonly refer to with regards to using gists that way:
- Since the content of the code is no longer part of the post, it is not being indexed by search engines, and
- Since the content of the code is not part of the post, and since the embedding mechanism is JS based, people who consume the blog via the feed and use feed aggregators that does not run javascript (most of them don’t), will not get the contents.
My answer to the first one is simple. I don’t really care. Not that I do not care about SEO, just that I do not need to have my post indexed and tagged under a bunch of irrelevant reserved words and common code. If the snippet is about using an interesting component ABC, I will mention that said ABC in the post content outside of the snippet, problem solved.
The latter is more interesting. I used to manually add a link to the gist page whenever embedding one, but it is not a very fun thing to do.
So, in order to overcome this, I wrote a small code snippet (yey) that upon saving a post (or updating it), will look for gists embeds, grab the gist source from github, stick in into the post as a “ContentForFeed” and serve with a link to the gist page, just for the fun of it.
And the code for it (it’s a hacky c#, but easily translatable to other languages, and/or to a cleaner form)
Have fun reading snippets
Determining SQL Server edition
Thanks to http://support.microsoft.com/kb/321185 and to Ariel (@Q) who have read it more carefully than I did, I learnt that there is a SERVERPROPERTY that you can query:
SELECT SERVERPROPERTY ('edition')
I expected to find Developer, but found Express instead.
MySQL error 105 - Phantom Table Menace
MySQL is weird The weirdest problem happened to a college today.
When creating the database schema during integration tests run, he got “Cannot create table FOO error 105” from MySQL.
There used to be a table named FOO with a VARCHAR primary key. The schema then changed so that the primary key of FOO became BIGINT. There is also a second table in the system (call it BAR) which has a foreign-key into FOO’s primary key. A classic master/details scenario.
However, the table BAR was obsoleted from the schema.
The integration tests runner is dropping all tables and recreating them before running the test suite. It is inferring the schema from the persisted classes using NHibernate’s mapper and the Schema creation feature of NHibernate. Sleeves up We cranked open the mysql console and started to look around:
- When doing “SHOW TABLES”, the FOO table was not listed.
- CREATE TABLE FOO (
IdBIGINT) - fail with error 105. - CREATE TABLE FOO (
IdVARCHAR) – success !! - huh?
- DROP TABLE FOO – success
- encouraging !
- CREATE TABLE FOO (
IdBIGINT) - fail with error 105 – again - huh ???
- DROP TABLE FOO – fail with “cannot delete … foreign key …”
- but SHOW TABLES still does not list FOO
- huh ?????
- DROP DATABASE dev; CREATE DATABASE dev;
- now everything works. Back to work Luckily this was not a production database, and even more lucky – the said DB change (change that PK from VARVHAR to BIGINT) would need to run on production within a separate DB instance that can be recreated on deploy.
And while we’re at it
Way can’t MySQL store non-indexed columns in an index?
ASP.NET MVC3 Model Validation using Interface Attributes
After reading Brad Wilson’s post on that, I thought to myself:
Brad is 100% correct regarding the way the CLR treat interface attributes, but this does not mean the users should not be able to use validation attributes on model interfaces
So I sat down to extend the model validation to do just that: (see https://gist.github.com/1163635 if it is broken here)
Now I know it is hacky – it should not go on a FilterAttributes() method. If I had access to the sources I’d have added a virtual “GetValidationAttribute” method on DataAnnotationsModelMetadataProvider… (hint hint hint)
Count number of times a file has been download via HTTP logs - DOS edition
Apparently you can also do this with DOS, but it is not nearly as easy as it is with Unix shells or Poweshell.
DOS corner: Good old DOS have FINDSTR which is quite similar to ‘grep’ but does not have anything to resemble ‘wc –l’. However, the FIND command can count occurrences so
type log_file | find /c url
would work – for a single file.
in order to do that for all files, an on-disk concatenated version would need to be created and removed. Here’s a batch file to accomplish this:
@Echo offpushd C:\inetpub\logs\LogFiles\W3SVC1if exist all.log del all.logcopy /a *.log all.log > nultype all.log | find /c %1del all.log > nulpopd
yuck? indeed
Count number of times a file has been download via HTTP logs - IIS and powershell edition
Following ben hall’s post (great blog – subscribe!) on counting file access data from Apache logs using *nix commanline’s grep, I thought to see how easy would it be to get the same with Powershell (I’ve been wanting to learn PS for ages – I have a few Windows servers I manage, and I love *nix commandline and miss it on these machines).
Smoking pipes I also wanted to be more idiomatic – looks like shell scripting (both with bash and friends, as well as with Powershell) favor piping outputs to inputs.
for e.g. – the command that Ben is using – reading the file using grep’s switch,
grep –o url log_file | wc -l
would be rewritten as
cat log_file | grep url | wc -l
Not being a unix master myself, I cannot tell which is better, but personally I prefer the latter; instead of needing to remember grep’s switch, I pipe cat into grep.
It becomes even better once going through multiple files – I have no idea what grep’s syntax for that is, but I can pipe ‘ls’ into ‘cat’
WRONGcat does not except input as a pipe. You need to resort to other syntaxes (see http://stackoverflow.com/questions/864316/how-to-pipe-list-of-files-returned-by-find-command-to-cat-to-view-all-the-files)
anyway, Powershell-ing First – ‘count strings’ is done by Select-String (this is the one of two parts I needed googling for)
the equivalent for ‘cat’ is … (wait for it) … ‘cat’
so,
cat log_file | select-string url
will return all relevant lines
So how do you count lines (equivalent to ‘wc –l’) ? - there’s a command called ‘measure’
Now we are at
cat log_file | select-string url | measure
IIS logs vs apache’s Not sure about how Apache does things, but with IIS, the access logs are split by default on a daily basis. All logs per a website are within a designated folder (, so one needs to iterate over all of them to count access to a given url.
That’s where cat’s piping impediment could have been bothering, however with powershell – things are a bit easier – you can actually pipe ‘ls’ into ‘cat’ ! show me the codez already
ls C:\inetpub\logs\LogFiles\W3SVC1 | cat | select-string "e.js" | measure
does the trick !
Actually – there’s a little trick here to take this a step forward
As opposed to unix shells, powershell is object oriented, and has richer models over simple text lines.
meaning – the output of ‘ls’ in powershell is not simply the file-names, but rather FileInfo objects
So, what’s so good about it you ask?
select-string, when fed with FileInfo instances, knows to look for the string within the file’s content instead of its name!
so we can drop ‘cat’ for that purpose and the final version is:
ls C:\inetpub\logs\LogFiles\W3SVC1 | select-string "e.js" | measure
Windsor 3 is here
See the announcement and grab the latest beta bits.
http://groups.google.com/group/castle-project-users/browse_thread/thread/632ef8b47395736b
What’s new?
http://docs.castleproject.org/Default.aspx?Page=Whats-New-In-Windsor-3&NS=Windsor
Major kudos to Krzysztof Koźmic for running the Windsor show so smoothly.
btw – a new design to the castle project website is about to be launched. It looks awesome! I’ll update once its out
Installing older node.js with latest npm on osx
At the time I write this, Heroku support Node 0.4.7, however the latest release is 0.4.8
Installing in the usual way (brew install node) will bring 0.4.8 in, so instead I opted to download the .pkg for 0.4.7
Node.js was installed correctly, however, it came with an old version on npm (the package manager for node.js).
| Searching around for npm installation brought up downloading the sh script and executing it. The snippet is curl http://npmjs.org/install.sh | sh |
For *nix noobs – this mean that the content of the file at http://npmjs.org/install.sh will be pushed as input for sh which is the runner for .sh scripts.
The problem is that the script tries to delete old npm versions, but it fails to do so for lack of permissions. Usually one prefixes with sudo to make this work, however it still did not work for me. What I ended up doing is breaking the process in two – first download the script into a local file (curl http://npmjs.org/install.sh > install.sh) and then sudo sh install.sh
I should be starting a “tips” section on the blog.
The hungry fox jumped over the lazy mac

And I use mainly chrome for day-to-day. the FF window is only open for a secondary gmail account, and the occasional Firebug session
Google Reader bug leading to a glitch in my feed
I have recently change the blog engine, and as part of that move, the permalinks for posts changed a bit (removed the .aspx suffix, and also got rid of the www. prefix)
So, the atom feed now lists a different <id> tag for each entry (post).
Google Reader cache data on posts based on the id tag, therefore subscribers to my blog who are using Google Reader will probably see 20 new messages.
The real glitch though is a bug in Google Reader. As far as reader is concerned, the <updated> and <created> tags does not mean a lot. It uses the time at which it discovered the entry as its date, for display (and sorting). This is arguable, and their argue is solid - since feeds are (at least historically) primarily made for news, they wanted to disallow publishers to twist scoop times.
So, I can understand why all my last 20 entries re-appear with the same date.
The annoying part is that Reader chooses a weird way to sort them. It could have at least use the publish date as a secondary sort order.
So, sorry for the glitch, and for those of you coming to my site, sorry for the poor UI design - a full redesign is in the make and will be pushed as soon as I can.
To all wheel inventors who might be reading this

I know a few people that needs to exercise a Bart Simpson punishment for wheel inventing, NIH, and more. I also sadly know that this probably won’t help (as is the case with Bart’s recurring mischiefs).
via http://www.addletters.com/bart-simpson-chalkboard-wallpaper-generator.htm
Spot the bug … dynamic language slap-on-forehead moment
This is a view template rendering html. When running it, it caused the page to freeze (i.e. the page keeps loading).
<h3>Services</h3>
<% for (var ix=0; ix < view.services.length; ++i) { %>
<% var service = view.services[ix]; %>
<p> <%=service.name %> </p>
<% } %>
Took me a while to grasp it. I tried various things, thought that the templating-engine code was bad, blamed every line of code in the application, until I actually re-read the template code carefully
You see, the indexer is “ix” while the ++ is working on “i”.
Since it is Javascript, no “I do not know what i is” exception was thrown. Instead, the first time it was encountered, JS decided it equals zero, and then the poor thing just kept increasing, probably until it would have overflowed.
In case you have missed it, it was javascript. Not AspView, nor Jsp. I am using a new, super-simple javascript base templating engine, for places where embedding something like AspView would be an overkill, and using NVelocity would be as annoying as using NVelocity.
I hope to have it released as open source soon. Basically it is a simple transformer into simple JS code, and I’m using the supercool Jint libraryfor running it within .NET. I am also planning on making it available for Java at some point using Mozilla Rhino
Official c# driver for MongoDB from 10gen
The announcement is on the users list - http://groups.google.com/group/mongodb-user/browse_thread/thread/62b071549a95dd4a?hl=en
Until now the two offerings were Norm and mongo-csharp, both are excellent OSS projects with lots of contributions and very nice velocity. My concern there was always that although there is definitely a place for more than one flavour, as usage patterns and even personal taste differ and pleasing everyone in a single product is impossible (see on rubyland for e.g., – there are MongoMapper, and Mongoid, and there are even some more, less-widespread ones). The major difference is that since the core of the ruby driver is maintained in a single location (and backed by paid-developers thx to 10gen), the things that are the same across (mainly BSON, client-server setup, connection management) are not duplicated, so we get a fully featured, very robust, tested by many core, and it gets out very fast.
On the c# side of things, the implementation of replica-sets in the client took some time to emerge after the official support on the server side was out.
So, it is an exciting announcement for the .NET community. I hope that the current drivers will know to adapt the drivers to use the official core.
CDRW driven nostalgia–WinFX edition
I was looking in my box-with-old-cds to find a CDRW to burn some podcast episodes (I have a CD based MP3 player in my car) and I stumbled upon an old CDRW. Looking into the content before erasing, and I found there some early beta installations for WinFX – that is what .NET 3.0 used to be called. These files were from mid-2006.
so, 4 and something years ago I was all excited about the new, shiny things from MS. The farthest away I went was into some use of the Boo language, and starting with some .NET OSS hacking (AspView, and Castle in general)
These days I find myself using Ruby (go Sinatra), Python (for AppEngine), and even god forbid Java. git it is my SCM of choice, MongoDB and MySql for data storage, etc.
I still find the .NET environment most productive, with a high quality core and superb language support, but I certainly have expanded my horizons to other areas.
I wonder what my areas of interests would look like on 2014 …
The big development machines survey
All right, not that big.
I’ve set up a simple survey about what development machine you use at work. If you are self employed and are using your personal machine for paid work, please state that in the comments field.
It is located at http://dev-machines.appspot.com/, go ahead and click your way into there.
Some explanations:
in the CPU slot, choose the CPU you have. the nC/mT bit on the Core i7 is about how many Cores and how many Threads the CPU support. Most i7 cpus has two cores, with hyperthreading, so the OS reports 4 cpus. There are some 4 cores models (with HT – the OS say 8) and a single model with 6 cores. You can browse this Intel’s page to get a feel about yours.
If you’re on an AMD, then just try to match the nearest option. I am not familiar with current AMD models, sorry.
This is the first time I deploy to google’s AppEngine, and the first time I am actually deploying python code as an application rather than automation scripts, so please be patient with possible failures.
TeamCity 5.1 + git + fix here + fix there
Finally.
I have a tiny project that need updating – the idcc.co.il website (*).
Source control I setup a new git repository on my home machine (using smart-http from git-dot-aspx, a different story for a different post) and now I got to setup a build server.
Team city Downloaded TeamCity 5.1.4 (the free, Professional version). Installation was mostly painless, except that the build-agent properties setter got stuck and I had to manually edit the build-agent conf file. No biggie – just RTFM: http://confluence.jetbrains.net/display/TCD5/Setting+up+and+Running+Additional+Build+Agents#SettingupandRunningAdditionalBuildAgents-InstallingviaZIPFile.
git integration Git is supported out of the box. I did have a minor glitch – the git-dot-aspx thing is very immature, and it simply did not work. Luckily the repository is located on the same machine as the build server and build agent so I simply directed the VCS root to the location on the filesystem.
building I had a few glitches with MSBuild complaining about missing project types (the webapplication targets file) – that’s the first three failures you see in the snapshot. I then copied the targets from somewhere else and I got the bulid running
Fixing the tests only to find that I have a broken test. Since when I created the initial website, I never set a build server, thus some changes I later introduced caused a minor regression. Now that I have a proper build server it (hopefully) won’t happen again.
- yes, Ohad and myself are setting up a second idcc conference. It is still in stealth mode, but keep you tabs of this. An announcement is planned for early October.
fixing text files to DOS style line endings - CRLF
Today I ran into a project that had mixed line-ending styles between files in the project. There were even a few files that had different type of line endings within the same file (bulk of lines with UNIX style, and other bulks with DOS style)
I ended up running the following c# “script” to fix that, and set all files to UTF-8 while I was at it.
The trick is to simply load the file with File.ReadAllLines which is indifferent when it comes to the line-ending type, and then write that back using WriteAllLines which will use the currently set Environment.NewLine value (which is CRLF when on windows)
The code is listed here; you can simply download a zip, open it to the folder of your choice and dbl-click it.
the only prerequisite is .NET 4.0 (I wanted the recursive and lazy Directory.EnumerateFiles)
The is listed here. It is generated by a javascript snippet so if you cannot see this in your offline feed reader, just go to the gist page
MongoDB 1.6 is out
A bit late, but I was pre-occupied with a few things so it went under my radar.
This release brings some exciting features, such as automatic-sharding and replica-sets, which completes MangoDB’s Horizontal Scalability and High Availability to a complete solution. A finer control over consistency is also available now, with the w option, with which you can assert update propagation to a certain amount of servers (so if you use replica sets of 3 machines, you might want to set w=2 or even 3, depending on your consistency needs).
These features, along with the fsync option, makes MongoDB a legitimate solution for both high-scale distributed data stores, as well as for small, single machine scenarios. Everyone can enjoy the simplicity of this DB engine.
As for using MongoDB from .NET, I’m still undecided between mongo-csharp or NoRM. I also successfully used IronRuby with MongoMapper and Mongoid, so at least we have plenty of options at our disposal.
What would make Razor really cool
The new thing in MS web development is Razor, which at its base a templating engine.
It would be really cool if:
- It would expose programmatic API (with c#5 going to Compiler-As-Service it would be a real shame if Razor would not behave the same way)
- It would not enforce an over bloated base-class (like, erm, System.Web.UI.Page). I wouldn’t go as far as an Interface (since looks like they do not believe in Design By Contract over there), but a super-simple abstract base class with minimal pre-set behaviour would be nice. It is doable with still supporting Webforms/MVC integration using wrappers (like the HttpContextBase approach)
These things would allow using it as a true templating engine, which then can be embedded as a view engine for other web frameworks (like Monorail and Fubu, and more), use it for off-line email templates processing, maybe even for emitting customised setting files for automated deployment scenarios.
I need to try and explore into there and sniff around.
The right tool for the job, XSS edition
It is not very uncommon to see pages that include a “returnUrl” parameter, usually within authentication flows. At times, the browser will run some script (like a call to an analytics service) and then another script issuing a redirect (through setting location.href etc.)
There are also other cases where UGC can find its way into JavaScript blocks. People might want to have their script do fancy stuff with the page’s data.
var url = '<%=viewData.returnUrl%>';
or
var commenterName = '<%=viewData.newComment.authorName%>';
for e.g.
Now for the “stating the obvious”:
Just like any other UGC, this type of content must be sanitized to prevent XSS attacks.
Not to long ago I was called to do a security inspection on a web application’s codebase. During which, some very few XSS holes were detected using JavaScript injection. This was quite surprising to me, as I knew that all content injected into JavaScript was being sanitized by the team.
Digging further I found out that they did call a sanitize function on UGC, just not the correct function. What they did was to run a JSON formatter over the UGC string, a thing that was solving JS errors occurring from string quoting problems, but it did not eliminate malicious scripts.
The weird thing was that the team was already using the AntiXss library (which is a very aggressive, white list based input sanitation library for .NET), for html fragments. The library also have a JavaScript Encode function. Switching the sanitation function of the team from calling the JSON library to calling the AntiXss library fixed the problem for good.
e.g. code to demonstrate the difference between the methods:
static void Main()
{
var ugc = "';alert('xss');'";
Render(JsonConvert.SerializeObject(ugc));
Render(AntiXss.JavaScriptEncode(ugc));
}
static void Render(string encoded)
{
Console.WriteLine("var returnUrl = '"+encoded+"';");
}The output from the above snippet is:
var returnUrl = '"';alert('xss');'"';
var returnUrl = ''\x27\x3balert\x28\x27xss\x27\x29\x3b\x27'';
There are a couple of things to learn from that story:
- When you encounter a problem, look around for common solutions. for e.g., every language that is being used for web development today has a library that takes care of XSS, so use it instead of coming up with a partial solution using the wrong library, or even worse –try to re-invent the way of doing that. You are probably not in the business of Anti XSS, so don’t spend time on solving the problem.
- Know your toolbox. If you are using a tool, be aware of its capabilities (and shortages). Exploring the AntiXss library a little bit would have shown the team that there is a perfectly good solution for their problem.
dotTrace 3.1 64bit would not integrate with Visual Studio and Resharper
Installed dotTrace 3.1
Since I run windows 7 64bit on my laptop, I chose to install the 64bit version of dotTrace. After the the installation, the standalone profiler worked great. It was also showing up in the Visual Studio AddIns menu. However, the purple button (next to the Debug “Play” button”) was greyed out, and the one within the Resharper Unit Testing sessions window was also disabled.
After re-installing, re-booting, and re-filling my cuppa’ coffee, I suddenly remembered that Visual Studio is actually a 32bit application, and that I’d probably want to install the 32bit version of dotTrace if I want them both to play nicely.
Did it.
Problem solved.
FYI
Can you spot the bug?
Can you spot what will cause the following NUnit test not to run on TeamCity 4.5?
[TestFixture("Testing some cool things")]
public class CoolThingsFixture
{
[Test]
public void When_Do_Expect()
{
Assert.That(2, Is.EqualTo(1+1));
}
}
hint: TeamCity list it with the ignored tests, yelling “No suitable constructor was found”
What’s new in Monorail 2.0
During the long, long time it took to get from 1.0RC3 to 2.0, many things have changed, and many things were added. I probably won’t cover it all in this post, and I’ll probably forget a few things that I got so accustomed to use (I have always used trunk versions, even way before I became a committer).
Programmatic config If (like me) you do not like putting stuff in config files that the operations team do not care about, you can now run a Monorail application without the Monorail section in the web.config file.
How? you’d need your Global class to implement IMonoRailConfigurationEvents.
e.g. from many of my websites: (I’m configuring AspView as view-engine)
public void Configure(IMonoRailConfiguration configuration)
{
configuration.ControllersConfig.AddAssembly(Assembly.GetExecutingAssembly());
configuration.ViewEngineConfig.ViewPathRoot = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "Views");
configuration.ViewEngineConfig.ViewEngines.Add(new ViewEngineInfo(typeof(AspViewEngine), false));
}
you can setup many optional things that way. e.g.:
// configue jquery as the validation engine
configuration.JSGeneratorConfiguration.AddLibrary("jquery-1.2.1", typeof (JQueryGenerator))
.AddExtension(typeof (CommonJSExtension))
.ElementGenerator
.AddExtension(typeof (JQueryElementGenerator))
.Done
.BrowserValidatorIs(typeof (JQueryValidator))
.SetAsDefault();
// configure url extensions
configuration.UrlConfig.UseExtensions = false;
delve into the intellisense on the IMonoRailConfiguration interface to find more
Return binders The example speaks for itself:
public class State
{
public string Code { get; set; }
}
[return: JSONReturnBinder]
public State[] GetStates()
{
// fake code for the sake of the demonstration
return new[] { new State { Code=“CA” }, new State { Code=“WA” } };
}
will render the JSON representation of the given State array
New routing engine see http://www.castleproject.org/monorail/documentation/trunk/advanced/routing.html
and http://kenegozi.com/blog/2009/02/10/monorail-routing-and-the-homepage-routing-rule.aspx for setting a homepage route
RescueController A rescue controller will take care of exceptions that have happened during an Action.
You’d create your rescue controller, implement IRescueController, inherit from SmartDispatcherController, and setup the rescue controller in the RescueAttribute on the regular controller.
see more here: http://www.castleproject.org/monorail/documentation/trunk/usersguide/rescues.html
AspView The C# based view engine became a first class citizen in Monorail. There has been many improvements there during the time, which deserve a separate post perhaps. meanwhile you can look at the aspview tag on this blog: http://kenegozi.com/blog/Tag/aspview.aspx
I can’t think of more stuff right now, so ping me if I forgot anything.
Monorail 2.0 – why the hell did it take so long
Being an Open Source project, with very good test coverage and a very active development, most users that actually run Castle bits in production were running off of trunk anyway.
The trunk is very stable, and the act of “release” should have simply been tagging any single commit to trunk as the 2.0 RTM.
However, we felt that we wanted some more stuff to justify a release – like updating the documentation, re-doing samples and Visual Studio integration packages, etc.
That lead us to a halt, as active committers did not use neither integrations nor samples, and same for the documentation. My personal stand was (and still is) that if someone wanted an official release so badly, then that one should contribute toward this, either with time and work, or with sponsorship money to buy this time and work.
No one did.
A few attempts at these parts was taken, but none concluded.
Meanwhile the project grew more and more, and parts of it became mandatory dependencies to various mainstream projects (such as NHibernate), while Windsor became more and more adopted as an IoC container of choice for many people.
Getting to a single point of approval across the board for the whole castle stack, without breaking third-party projects that depends on parts of Castle, became very difficult.
Breaking apart In order to allow a manageable release process, the project was broken down to its parts. Now we have the four main projects, released on their on, with depending projects using compiled releases of the others.
The main projects are:
- Core (de-facto including Dynamic Proxy) which is used on many other OSS projects
- ActiveRecord
- IoC stack (MicroKernel + Windsor)
- Monorail
More details can be found on the projects page of castle’s website
An all-trunk builds can be retrieved with the aid of the horn-get project.
So why is Monorail last? The reason is rather simple. Monorail depends on almost any other part of the stack. It even has subprojects such as ActiveRecord’s DataBinder (ARDataBind) which depends on ActiveRecord, and a WindsorIntegration project which depends on the IoC stack.
As a result we had to wait to get releases for all other projects.
What’s next? I still have no idea. There are a few discussions going on about that (such as this one on the new roadmap), and you are all welcome to join the debates.
Monorail 2.0 is out
After a long huge wait, finally Monorail 2.0 is out, get yours from https://sourceforge.net/projects/castleproject/files/
HUGE thanks to John Simons and the rest of the Castle project committers, plus the rest of the good people that have supplied us with patches, bug fixes, and whatnot.
This move somewhat concludes the move from the old 1.0RC3 release from 2007, to the new releases of the Castle stack about two years afterwards.
I’m going to follow up with a couple of “what’s new”, “how-to upgrade” and “why the hell did it take so long” posts soon, so keep watching.
AutoStubber to ease stub based unit tests
Tired of setting up stubs for your class under test?
Tired of compile errors when you add one more dependency to a class?
The AutoStubber to the rescue.
Given
interface IServiceA
{
string GetThis(long param);
}
interface IServiceB
{
Do DoThat(string s);
}
class MyService
{
public MyService(IServiceA a, IServiceB b) { ... }
...
}
...
you can write;
var service = new AutoStubber.Create();
// Arrange
var theString = "whatever";
service.Stubs().Get.Stub(x=>x.GetThis(0).IgnoreArguments().Return(theString);
// Act
service.Execute();
// Assert
service.Stubs().Get.AssertWasCalled(x=>x.DoThat(theString);
The code for AutoStubber:
- Mind you – it’s not the prettiest, but it gets the job done
public class AutoStubber<T> where T : class
{
static readonly Type TypeofT;
static readonly ConstructorInfo Constructor;
static readonly Type[] ParameterTypes;
static readonly Dictionary<object, AutoStubber<T>> Instances = new Dictionary<object, AutoStubber<T>>();
static AutoStubber()
{
TypeofT = typeof(T);
Constructor = TypeofT.GetConstructors().OrderByDescending(ci => ci.GetParameters().Length).First();
ParameterTypes = Constructor.GetParameters().Select(pi => pi.ParameterType).ToArray();
}
public static AutoStubber<T> GetStubberFor(T obj)
{
return Instances[obj];
}
bool _created;
public T Create()
{
if (_created)
throw new InvalidOperationException("Create can only be called once per AutoStubber");
_created = true;
return Instance;
}
readonly Dictionary<Type, object> _dependencies = new Dictionary<Type, object>();
private T Instance { get; set; }
public AutoStubber()
{
var parameters = new List<object>(ParameterTypes.Length);
foreach (var parameterType in ParameterTypes)
{
var parameter = MockRepository.GenerateStub(parameterType);
parameters.Add(parameter);
_dependencies[parameterType] = parameter;
}
Instance = (T)Constructor.Invoke(parameters.ToArray());
Instances[Instance] = this;
}
public TDependency Get<TDependency>()
{
return (TDependency)_dependencies[typeof(TDependency)];
}
}
public static class AutoStubberExtensions
{
public static AutoStubber<T> Stubs<T>(this T obj)
where T : class
{
return AutoStubber<T>.GetStubberFor(obj);
}
}
I know there is the AutoMockingContainer, and various other stuff out there, but this thing just was very natural to me, it uses a very simple API (do not need to keep reference to the Container), and took me less than an hour to knock off.
An enhancement I consider would be to allow setting pre-created values to some of the parameters. But meanwhile I did not happen to need it.
Quoted
I’ve just found out that my I’m being *quoted in a book !
the book is Testing ASP.NET Web Applications (Wrox Programmer to Programmer)
So You Think You’re A Web Developer series. Plus anyone investing time in Web apps testing is a worthy man, not to mention a guy that invests time in educating people into testing their web apps.
- Actually, it’s not anything smart that I’ve been saying, but rather my simple IoC implementation, which I originally created for a tiny project that couldn’t have had *any 3rd party dependency (including Windsor), and is now being used as a manner of teaching what an IoC is and how it can help you. neat, and thx for the credit.
Windsor’s Logging Facility; getting a named instance
When using Windsor’s logging facility, you’d usually take a dependency of an ILogger in your component, and have Windsor create the logger instance. The logger’s name will be of your component’s full type name.
e.g. for the following component:
namespace My.Application
{
public class UsingLogIntegration
{
readonly ILogger logger;
public UsingLogIntegration(ILogger logger)
{
this.logger = logger;
}
}
}
The logger’s name will be My.Application.UsingLogIntegration
At times, you would need to get a logger in a different way, either because you’d want a special name, or you will be in a location where you cannot have Windsor resolve that for you as a dependency (say within an ASP.NET’s Global.asax class, which gets instantiated by ASP.NET, not by Windsor).
The naive approach would be to ask the container for an ILogger, however if you’d try this, you’ll discover that Container.Resolve<ILogger>() will not fit your needs. So what will you do?
Well, the facility also sets an ILoggerFactory, which is in charge of creating loggers. So, do that instead:
var loggerTypeOrName = GetTheTypeForTheLoggerOrAStringIfYouPrefer();
var logger = Container.Resolve().Create(loggerTypeOrName);
ILoggerFactory.Create() can live with a type (will use the full type name as name) or with a string.
Castle Windsor and the LoggingFacility
So you want to be able to do some logging from your code.
log4net for example, is a very common logging framework for .NET, and using it is pretty straight forward, and the net is full of log4net intros.
Usage example:
namespace My.Application
{
public class UsingLog4netDirectly
{
private static log4net.ILog logger = log4net.LogManager.GetLogger(MethodBase.GetCurrentMethod().DeclaringType.FullName);
...
...
...
}
}
However, there are some caveats with using it directly.
- You get a hard dependency on log4net’s dll
- You need to manually setup the logger instance with logger name for each class – that’s both annoying and error prone
- And has bad impact on testing.
Windsor, once again, can help a lot with making it much easier. e.g:
namespace My.Application
{
public class UsingLogIntegration
{
readonly ILogger logger;
public UsingLogIntegration(ILogger logger)
{
this.logger = logger;
}
...
...
...
}
}
Windsor will take care of injecting the correct logger instance, with the name set correctly (using the class name, not needing the wacky MethodBase… stuff)
So, what do you set this up?
Required assemblies: Assuming you already use Windsor, you need
- Castle.Facilities.Logging (the logging facility)
- Castle.Services.Logging.Log4netIntegration (or any other built-in or custom made Integration)
- log4net.dll (or any other actual logger implementation)
You actually do not need to reference these assemblies, only make sure they are on the application’s bin folder. If you use the programmatic configuration (like I do), you’d also need the first (the facility) referenced from your code.
Registration:
container.AddFacility("LoggingFacility", new LoggingFacility(LoggerImplementation.Log4net));
and … that’s it !
You still need to setup log4net’s configuration, and tell the application where it is:
log4net.Config.XmlConfigurator.Configure();
Get a different logger for tests Easy. Instead of configuring the facility, you simply configure another implementation.
container.Register(Component.For().Instance(new ConsoleLogger()));
If you’d explore the Castle.Core.Logging namespace you’d find few, very useful built-in implementations, such as a NullLogger (which you get by calling NullLogger.Instance), ConsoleLogger, StreamLogger (write to a file or memory stream), TraceLogger (writes to the diagnostic trace output) and WebLogger (writes to the HttpContext’s Trace, visible at trace.axd).
Copy and Paste an image from Word2007 to Paint.NET
Scenario: I got a docx document by email, with an image embedded inside. I needed to take it to Paint.NET for some cropping and resizing. Usually I’d copy the image, then “Paste as New Image” on Paint.NET (using Ctrl+Alt+V, or the Edit menu). Problem: Paint.NET did not recognize the clipboard content as a valid image. Solution: I pasted the image into the good ol’ Paint.exe, then copied from there, and “Pasted as New” in Paint.NET
voila.
chrome address box wtf

I should start a wtf tag here …
Chrome 3 appear to be just around the corner.
I’m switching now.
UPDATE: so far Chrome 3 is stable.
Accessing a specific revision of SVN repository through the browser
Just throw ‘!svn/bc/REVISION_NUMBER/’ to the url, right after the repository root
thx gooli for the superb tip.
MySql won’t start – Error 1067
We’re using MySql at work, and for that I installed 5.1 on my workstation (Windows 7 RC x64), with all the defaults (next, next, next, …, finish)
Being environmentally friendly (or mentally instable – depends on who you’re asking), I tend to shut down my workstation when I go home at the end of every day.
So – today, when first navigating to a url served by my local working copy, I was greeted with a SystemException telling me that MySql is not responding.
My first reaction was WTF
My following reaction was
Win-R cmd net start mysql
Surprisingly enough, instead of the laconic OK, I was greeted with:
The MySQL service could not be started.
A system error has occurred.
System error 1067 has occurred.
My next reaction was back to WTF.
Goggling around I found no meaningful answer, so I went for uninstall/reinstall.
So, Win+MySql (to look for an uninstaller in the Start Menu, lazy me) I stumbled upon “MySQL Server Instance Config Wizard”
This dude apparently can re-do the Instance Configuration thing, and running it (again with the next, …, next, finish ritual) appear to have fixed the problem.
After all I do have something nice to say about MySql. when weird shit happen, there is a tool to make instance re-install rather painless.
All the rest about it is crap.
[not] storing data in DOM elements - jQuery.data function
At time you’d want to store data, related to a DOM element.
storing it directly into the element (either by elm.someArbitraryName = value, or with setAttribute) is wacky. Some browsers might not like you using non standard attributes, so you start using things like ‘alt’ and ‘rel’. Then again, these things has meaning, and storing arbitrary data is … well, uncool to say the least.
jQuery.data() to the rescue. As jQuery objects are wrappers that HasA DOM elements, and not the DOM elements themselves (as in prototype), storing data on them is like storing data on POJSO (Plain Old JavaScript Objects), and the data() functions allows for an easy way of doing that.
Read on that (and of a few other jQuery tips) at http://marcgrabanski.com/article/5-tips-for-better-jquery-code
Taking GoGrid for a spin - first impressions
Today I opened a GoGrid account, as I’m looking for quite some time to upgrade my hosted environment.
Setting up the account was a breeze, and in a few minutes from starting the process I had a running instance of vs2008 64bit, with IIS and MSSql2005 express.
First impressions:
Good:
- Quick, easy to use control panel, pricing seem reasonable
- The image contains .net 3.0, and lack some updates so 3.5 was not installing until I allowed all of the windows update stuff to do the magic first.
- Online chat is helpful and very responsive. I did not need any actual tech help yet though.
Bad:
- They charge for offline machines, so you can’t just turn on and off the machines, but you have to delete machines that are not in use, and in case you want to re-add them you have to recreate a new machine from their image, then running updates, installs, DB setup etc from scratch
That’s it for now
D9 - Yet another tools project
I’ve started a new oss project under the name “D9”.
the project is hosted at http://code.google.com/p/d-9/
I’m adding all kinds of useful stuff I’ve written during my years doing .NET, that I didn’t have any better place for.
It’s fairly empty now, but during the following days I hope to add more stuff in there.
Currently you can find:
- D9.Commons - well, common stuff. Things that need no reference outside the BCL.Currently the only thing there is a helper for using the DescriptionAttribute on enum values. more to come
- D9.NHibernate - helpers for NHibernate development. The only thing there currently is a UserType that allow persisting enums using their DescriptionAttribute instead of their name
- D9.StaticMapGenerator - I’ve written about this before. It’s a command-line tools that generates a strongly type sitemap for a website’s static files (css, js and image files)
What I’m gonna add shortly:
- D9.QuerySpecBuilder - a library for generating SQL code in a structured Criteria-like manner
I generally am doing this so I’ll have a place for all my recurring stuff (instead of copy&pasting from project to project every now and then). If people will find it useful it’d be great. If people will want to contribute to it it’d be even greater.
License is “new BSD” so feel free to use it if you like
comments, endorsements and insults are welcome as always.
IoC.NET Smackdown
I’ve just came across a comparison on IoC containers in the .NET world:
- http://blog.ashmind.com/index.php/2008/08/19/comparing-net-di-ioc-frameworks-part-1/
- http://blog.ashmind.com/index.php/2008/09/08/comparing-net-di-ioc-frameworks-part-2/
Haven’t read it yet cuz Im actually off-computer right now (the lappy is attached to the living room TV, and the break in the movie is almost over), but MAN is has COLOUR charts, so you can bet your arse I’m gonna read it later.
Not that I’m excited. I’m pretty sure that (INSERT WINNER HERE LATER) will prove to be the best IoC ever.
FactorySupportFacility gotcha
The FactorySupportFacility in Windsor is very useful but there’s a little something to be aware of when using it.
What is it? This facility allows you to tell the container that when a given service is to be resolved, instead of new-ing it, it should call a factory method to obtain an instance.
This is very useful for context objects (like DbContext, HttpContext etc.) , which are usually being supplied by a framework thus you can’t have the container instantiate them directly. So, assuming you want to inject a ISomeContext object into a service, you need to create a factory that can obtain it for you:
public class SomeContextFactory
{
ISomeContext ObtainFromFramework()
{
return SomeFrameworkContext.Current; //or whatever
}
}
then you can setup the container to use that factory when injecting the context
The usage: Online examples:
- http://www.jroller.com/hammett/entry/castle_s_factory_facility(using XML config, and it’s somewhat old - that’s the first announcment of this facility from Hammet back in the mesosoican era).
- http://mawi.org/ProgrammaticCastleMicrokernelWindsorAmpTheFactoryFacility.aspx(using programmatic container initialisation).
And, the gotcha: When taking the programmatic road, you must follow this order of doing things:
- Create the facility instance:
var facility = new FactorySupportFacility();
- Add it to the container
container.Kernel.AddFacility("factory.support", facility);
- Register your factories in the facility:
facility.AddFactory<ISomeContext, SomeContextFactory>("some.context", "ObtainFromFramework");
If you mix 2 and 3, it would break.
There reason of course is that registering the factory into the facility, mean that the facility needs no know about the current container and kernel. This is being done in step 2 so you simply can’t do step 3 before that.
On google insights - do numbers always count?
A dude on the ALT.NET Israel mailing list has given the new Google Insights a few things to chew on.
For example, he’s shown that there is much more interest in ASP.NET MVC over MonoRail.
So a wonder came up, whether one should choose a framework or a technology should it be highly searched for.
my take on the matter:
- even if many people have searched for A, they might have found it, and decided against it.
- even if many of them do like or work with A, it doesn’t mean it’s right for me.
I’d look for this type of people in the tech community.
People that:
- Are very professional, highly skilled, ones I do want to get help from;
- Have shown interest in helping the community, rather than asking questions.
- Can, on top of answering questions and giving advice, fix and improve the said technology themselves or using my suggestions/patches on the spot thus improving my productivity
No matter how you’d turn the search statistics, based on parameter 3 only, any OSS will be way ahead a closed source solution.
Gustavo Ringel also had a say:
I see a lot of articles about how to do stupid things with typed datasets, and much less about how to do great things with ORM’s…should i had go for typed datasets instead of NHibernate or other ORM because i have more help of less skilled people?
Skype addon for FireFox has killed Google Maps
I’m a big fan of google maps. A simple and yet very effective tool. I wish they had maps for Israel too …
Anyway, I noticed today that the maps do not load on my FF. started disabling addons one by one (you’d usually blame FireBug …) but I found out that it was the skype plugin’s fault.
hmm. Im not really using it much anyway, and for the rare cases I do need to phone someone abroad, I guess I’ll copy and paste into skype.
Patch management approaches using decent CSM
Following Ayende’s post on Patch management approaches using centralized SCM, here are how I would have dealt with the 4 issues that he brings up, using a Decentralised SCM.
I use git, so I’ll use git terms here. I guess it’s quite similar for other DSCM systems.
Note that I haven’t used patches on git development as until now all of my git work was on repositories I had write access to, However the principals are the same (i.e. - all of the tree is local to my machine, thus I can reach any point in the history locally).
First I’ll clone the hosted repository to my local machine.
- #1 I’d have created a separate local feature branch for each feature, so separating the patches is easy
- #2 again, I can do this in two separate local branches, so I do not need to "revert and apply" when I move between the two. I also get to have a complete SCM experience, not only a single patch/step per feature. I can also have a third branch, combining the work of the two feature branches, for my own use
- #3 the second feature’s branch would be based on the first one. should the first need some rework that is important to the second, it’d be easy to apply changes on the first, then rebase the second ontop of the updated first
- #4 just two commits on the same branch.
So, using a DSCM, I can work locally with the benefits of a SCM, have as many branches/features as I want. the whole tree is stored locally, and its blazing fast to switch branches, so I can easily work on every aspect I want, and easily create a patch from every node in the history tree, to send to the project owners.
Simple String Hashing in .NET
I’ve been asked about it several times lately, so I’ll just put here an oldie that I’ve been using for a few years now untouched:
1: // MIT license 2: // Copyright 2005-2008 Ken Egozi 3: // 4: // Permission is hereby granted, free of charge, to any person obtaining a copy 5: // of this software and associated documentation files (the "Software"), to deal 6: // in the Software without restriction, including without limitation the rights 7: // to use, copy, modify, merge, publish, distribute, sublicense, and/or sell 8: // copies of the Software, and to permit persons to whom the Software is 9: // furnished to do so, subject to the following conditions: 10: // 11: // The above copyright notice and this permission notice shall be included in 12: // all copies or substantial portions of the Software. 13: // 14: // THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR 15: // IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, 16: // FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE 17: // AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER 18: // LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, 19: // OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN 20: // THE SOFTWARE. 21: 22: using System; 23: using System.Collections.Generic; 24: using System.Text; 25: using System.Security.Cryptography; 26: using System.Collections; 27: 28: namespace KenEgozi.CryptographicServices 29: { 30: publicstaticclass Hashing 31: { 32: privatestatic Hashtable hashAlgorithms = Hashtable.Synchronized(new Hashtable()); 33: 34: /// <summary> 35: /// Hashing a given string with SHA2. 36: /// </summary> 37: /// <param name="data">Data to hash</param> 38: /// <returns>Hashed data</returns> 39: publicstaticstring HashData(string data) 40: { 41: return HashData(data, HashType.SHA256); 42: } 43: 44: /// <summary> 45: /// Hashing a given string with any of the supported hash algorithms. 46: /// </summary> 47: /// <param name="data">Data to hash</param> 48: /// <param name="hashType">Hashing algorithm to use</param> 49: /// <returns>Hashed data</returns> 50: publicstaticstring HashData(string data, HashType hashType) 51: { 52: HashAlgorithm hash = GetHash(hashType); 53: byte[] bytes = (new UnicodeEncoding()).GetBytes(data); 54: byte[] hashed = hash.ComputeHash(bytes); 55: StringBuilder sb = new StringBuilder(64); 56: foreach (byte b in hashed) 57: sb.AppendFormat("{0:x2}", b); 58: return sb.ToString(); 59: } 60: 61: privatestatic HashAlgorithm GetHash(HashType hashType) 62: { 63: if (!hashAlgorithms.ContainsKey(hashType)) 64: hashAlgorithms.Add(hashType, CreateaHashAlgorithm(hashType)); 65: return hashAlgorithms[hashType] as HashAlgorithm; 66: } 67: 68: privatestatic HashAlgorithm CreateaHashAlgorithm(HashType hashType) 69: { 70: switch (hashType) 71: { 72: case HashType.MD5: 73: returnnew MD5CryptoServiceProvider(); 74: case HashType.SHA1: 75: returnnew SHA1Managed(); 76: case HashType.SHA256: 77: returnnew SHA256Managed(); 78: case HashType.SHA384: 79: returnnew SHA384Managed(); 80: case HashType.SHA512: 81: returnnew SHA512Managed(); 82: default: 83: thrownew NotImplementedException(); 84: } 85: } 86: } 87: 88: publicenum HashType 89: { 90: MD5, 91: SHA1, 92: SHA256, 93: SHA384, 94: SHA512 95: } 96: }Not beautiful, however useful.
You can download this file from here (just remove the .txt - the server doesn’t serve .cs files directly)
btw, the colouring of the source was made with the help of http://www.manoli.net/csharpformat/, even though I had to do some manual tweaking to make it work with this blog. If colours of reserved words, comments etc. do not appear, then please refresh your browser’s cache to get the updated css
Castle.Tools.* in Castle Contrib's repository has moved a bit
The tools (various small helper libraries) are now under http://svn.castleproject.org:8080/svn/castlecontrib/Tools/
what’s in there:
- Castle.Tools.StaticMapGenerator - That one creates a typed tree representing js/css/image files on the site’s filesystem. more here:http://kenegozi.com/Blog/2008/01/17/staticmapgenerator-for-asp-dot-net-first-teaser.aspxWhich reminds me that I need to add .swf files to the mix …
- Castle.Tools.SQLQueryGenerator - That one is for building plain old SQL strings in a typed and intellisense friendly way.more here:http://kenegozi.com/Blog/2008/01/27/already-added-stuff-to-sql-query-generator.aspx
- Castle.Tools.QuerySpecBuilder/ - The new kid in the block. That’s a tool that is used to build specs programmatically, which would later be translated to a SQL string for your flavour of DAL. The generated SQL is mostly ANSI compliant, apart from the Paging syntax which is TSQL only currently, but at some point I’ll add an extension point to allow other syntaxes.I also have an external thing to make it extremely useful with NHibernate’s ISQLQuery.I’ll blog about all that when I’ll have a little time.
The Fox Is Hungry
My impression on Firefox 3 by now:
- It looks nicer.
- It still eats up all of my poor machine’s memory
Download Firefox 3
I really don’t need to add anything, right?

Installed it myself today. Appear to be a bit faster, and to eat up less memory.
The Google Toolbar and FireFTP were updated automatically.
I needed to manually re-install FireBug and IE-Tab
btw, does anybody know where did the Back and Forward buttons has gone to? Im using the keyboard usually, but sometimes (especially during in-office-lunch-time) I need to click the Back thing with the mouse
UPDATE: it appear that as part of the upgrade, FF3 has inherited my customised toolbars and that’s why it was looking weird. So I right-clicked on the toolbar -> customise, the clicked “Restore Default Set”. All the buttons came back, then I rearranged the toolbar to my liking.
Logging SQL output from NHibernate, using Log4Net
Following a question from NHibernate’s users list:
<configSections> <section name="log4net" type="log4net.Config.Log4NetConfigurationSectionHandler,log4net" /></configSections><log4net> <appender name="rollingFile" type="log4net.Appender.RollingFileAppender,log4net" > <param name="File" value="log.txt" /> <param name="AppendToFile" value="true" /> <param name="DatePattern" value="yyyy.MM.dd" /> <layout type="log4net.Layout.PatternLayout,log4net"> <conversionPattern value="%d %p %m%n" /> </layout> </appender> <logger name="NHibernate.SQL"> <level value="ALL" /> <appender-ref ref="rollingFile" /> </logger></log4net>
and configuring your application to use Log4Net (if you hadn’t done that anyway):
log4net.Config.XmlConfigurator.Configure();
If you wan’t to know more about log4net and it’s configuration options - look here or use your favorite search engine.
AgentSmith - Resharper plugin
From the website:
Current version includes following features:
-
Naming convention validation.
-
XML comment validation.
-
XML comment, string literals, identifiers and resources (.resx files) spell checking
Smart paste.
The coolest thing is the ability to spell check identifiers. I’d love it.
It’s at http://www.agentsmithplugin.com/ and I found out about it on Castle’s dev list (thx Victor)
[Tool] - Visual XPath
As I’m trying to avoid xml files as much as possible, when I do find the need to xpath, I always need to refresh my memory on the matter.
Today I’ve been working with kml files, and the need for some simple xpath queries came up, forcing me to do some trial-and-error in an area I don’t really like …
Next time I’ll have Visual XPath to help me with that.
SQL Query Generator - First Release
What is it? A tool that generates a strongly typed representation of a relational database, to be used for generating SQL queries in a type-safe fashion, with the aid of intellisense.
Where to get it?
- Current Binaries: from here
- Source code: http://svn.castleproject.org:8080/svn/castlecontrib/Castle.Tools.SQLQueryGenerator/trunk/
UPDATE (22/06/2008):The source has slightly moved (to a sub folder):http://svn.castleproject.org:8080/svn/castlecontrib/Tools/Castle.Tools.SQLQueryGenerator/
Limitations:
- Currently works only with SQL Server 2005. Patches for more DB types would be welcomed.
- Currently only SELECT queries are implemented. Soon I’ll add support for generating INSERT, UPDATE and DELETE, too.
- GroupBy, Order By and Having clauses didn’t make it to this initial release. I hope to add those this week.
How to use it?- Generating the classes:Run Castle.Tools.SQLQueryGenerator.exe.Parameters:The mandatory flag is /db:DBNAME where DBNAME is your database name. By default, the server being looked for is (local). you can select another using /server:SERVER.By default, Integrated Security is used. You can supply /userid:USER and /password:PASS to override it.You can alternatively supply a /connectionstring:CONSTR parameter.
- Add the generated file, named “SQLQuery.Generated.cs” to your project.
- Add a reference to Castle.Tools.SQLQueryGenerator.Runtime.dll
- Use and Enjoy
Usage sample (from Examples.cs in the test project:
SQLQuery q = SQLQuery .Select(SQL.Blogs.Id, SQL.Blogs.Name) .From(SQL.Blogs);Console.WriteLine(q);
Would print out:
SELECT [dbo].[Blogs].[Id], [dbo].[Blogs].[Name]FROM [dbo].[Blogs]
Not impressed? Well,
dbo_ForumMessages Message = SQL.ForumMessages.As("Message");dbo_ForumMessages Parent = SQL.ForumMessages.As("Parent"); SQLQuery q = SQLQuery .Select(Message.Id, Message.ParentId, Message.Content) .From(Message) .Join(Parent, Message.ParentId == Parent.Id);Console.WriteLine(q);
Will spit out
SELECT [Message].[Id], [Message].[ParentId], [Message].[Content]FROM [dbo].[ForumMessages] AS [Message] JOIN [dbo].[ForumMessages] AS [Parent] ON ([Message].[ParentId] = [Parent].[Id])
Need parameters?
Parameter<int> blogId = new Parameter<int>("BlogId"); SQLQuery q = SQLQuery .Select(SQL.Blogs.Id, SQL.Blogs.Name) .From(SQL.Blogs) .Where(SQL.Blogs.Id == blogId);Console.WriteLine(q);
would echo
SELECT [dbo].[Blogs].[Id], [dbo].[Blogs].[Name]FROM [dbo].[Blogs]WHERE ([dbo].[Blogs].[Id] = @BlogId)
How can YOU help?- Use it. Praise it. Use Paypal.
- Or you can suggest improvements, spot bugs, create patches and buy me beer.
Already Added Stuff To SQL Query Generator
the new stuff:
- Reusing clauses
-
Operators ( , &&, !) on where clause - OrderBy clause
Examples:
Reusing clauses:
FromClause from = new FromClause(SQL.Blogs);WhereClause where = new WhereClause(SQL.Blogs.Id == 2); SQLQuery q1 = SQLQuery .Select(SQL.Blogs.Id) .From(from) .Where(where); SQLQuery q2 = SQLQuery .Select(SQL.Blogs.Name) .From(from) .Where(where); Console.WriteLine(q1);Console.WriteLine(q2);
makes
SELECT [dbo].[Blogs].[Id]FROM [dbo].[Blogs]WHERE ([dbo].[Blogs].[Id] = 2)SELECT [dbo].[Blogs].[Name]FROM [dbo].[Blogs]WHERE ([dbo].[Blogs].[Id] = 2)
Operators:
SQLQuery q1 = SQLQuery .Select(SQL.Blogs.Id) .From(SQL.Blogs) .Where(SQL.Blogs.Id > 2 || SQL.Blogs.Name == "Ken");Console.WriteLine(q1);
makes
SELECT [dbo].[Blogs].[Id]FROM [dbo].[Blogs]WHERE (([dbo].[Blogs].[Id] > 2) OR ([dbo].[Blogs].[Name] = N'Ken'))
OrderBy Clause:
SQLQuery q = SQLQuery .Select(SQL.Blogs.Id) .From(SQL.Blogs) .Where(SQL.Blogs.Id > 2) .OrderBy(Order.By(SQL.Blogs.Id), Order.By(SQL.Blogs.Name).Desc);Console.WriteLine(q);
makes
SELECT [dbo].[Blogs].[Id]FROM [dbo].[Blogs]WHERE ([dbo].[Blogs].[Id] > 2)ORDER BY [dbo].[Blogs].[Id], [dbo].[Blogs].[Name] DESC
Didn’t have time to upload a binary, but you can simply grab the source and build yourself. it has absolutely no dependencies but .NET 2.0
Where from?
http://svn.castleproject.org:8080/svn/castlecontrib/Castle.Tools.SQLQueryGenerator/trunk/
UPDATE (22/06/2008):The source has slightly moved (to a sub folder):http://svn.castleproject.org:8080/svn/castlecontrib/Tools/Castle.Tools.SQLQueryGenerator/
SQL Query Generator
Imagine you could write that in your IDE:
SQLQuery q = SQLQuery .Select(SQL.Blogs.Id, SQL.Blogs.Name) .From(SQL.Blogs) .Join(SQL.Posts, Join.On(SQL.Blogs.Id == SQL.Posts.BlogId)) .Where(SQL.Blogs.Name != "Ken's blog");
Console.WriteLine(q);
and getting that output :
SELECT [Blogs].[Id], [Blogs].[Name]FROM ([Blogs] JOIN [Posts] ON ([Blogs].[Id]=[Posts].[BlogId]))WHERE ([Blogs].[Name]<>'Ken''s blog')
Soon enough you would be able to to that.
After having fun creating the Static Sitemap Generator, today I’ve had a little free time (as my main machine is being reinstalled), so I came up with a SQL query generator.
It would be a tool to generate classes out of a database, that would make writing typed sql queries a breeze.
I have most of it working, except the part where I retrieve the metadata from the database … No worries, my good friend and SQL guru Moran is about to send me the queries for that real soon.
First release would work with SQL Server 2005, and later on I’ll add extension points to hook up other db engines.
Retrieving All Column Names And Types From SQL Server 2005 For .NET
Nothing fancy.
With a little help from Moran Benisty, here’s the script I use to get the metadata I need for the SQLQueryGenerator:
SELECT schemas.name AS [Schema], tables.name AS [Table], columns.name AS [Column], CASE WHEN columns.system_type_id = 34 THEN 'byte[]' WHEN columns.system_type_id = 35 THEN 'string' WHEN columns.system_type_id = 36 THEN 'System.Guid' WHEN columns.system_type_id = 48 THEN 'byte' WHEN columns.system_type_id = 52 THEN 'short' WHEN columns.system_type_id = 56 THEN 'int' WHEN columns.system_type_id = 58 THEN 'System.DateTime' WHEN columns.system_type_id = 59 THEN 'float' WHEN columns.system_type_id = 60 THEN 'decimal' WHEN columns.system_type_id = 61 THEN 'System.DateTime' WHEN columns.system_type_id = 62 THEN 'double' WHEN columns.system_type_id = 98 THEN 'object' WHEN columns.system_type_id = 99 THEN 'string' WHEN columns.system_type_id = 104 THEN 'bool' WHEN columns.system_type_id = 106 THEN 'decimal' WHEN columns.system_type_id = 108 THEN 'decimal' WHEN columns.system_type_id = 122 THEN 'decimal' WHEN columns.system_type_id = 127 THEN 'long' WHEN columns.system_type_id = 165 THEN 'byte[]' WHEN columns.system_type_id = 167 THEN 'string' WHEN columns.system_type_id = 173 THEN 'byte[]' WHEN columns.system_type_id = 175 THEN 'string' WHEN columns.system_type_id = 189 THEN 'long' WHEN columns.system_type_id = 231 THEN 'string' WHEN columns.system_type_id = 239 THEN 'string' WHEN columns.system_type_id = 241 THEN 'string' WHEN columns.system_type_id = 241 THEN 'string' END AS [Type], columns.is_nullable AS [Nullable]FROM sys.tables tables INNER JOIN sys.schemas schemas ON (tables.schema_id = schemas.schema_id ) INNER JOIN sys.columns columns ON (columns.object_id = tables.object_id) WHERE tables.name <> 'sysdiagrams' AND tables.name <> 'dtproperties'
ORDER BY [Schema], [Table], [Column], [Type]
Quick, Dirty, Working.
Anyone up to contributing a similar thing for SQL 2000 / MySql / Oracle / Postgres / MS-ACCESS ?
it’s going to be subversion-ed really soon.
YAGNI - My Tiny IoC Feels Lonely
It’s funny. At the end of the day, I didn’t use the tiny IoC in the StaticSiteMap for the testing.
It was fun however.
StaticMapGenerator Source Is Available
The Static SiteMap Generator’s home is in Castle Contrib, and it’s named Castle.Tools.StaticMapGenerator
I’ve just commited it to the repository, so it’s at http://svn.castleproject.org:8080/svn/castlecontrib/Castle.Tools.StaticMapGenerator/trunk/
UPDATE (22/06/2008):The source has slightly moved (to a sub folder):http://svn.castleproject.org:8080/svn/castlecontrib/Tools/Castle.Tools.StaticMapGenerator/
I hope to have time soon to blog about the creation of this little tool, and of the usage. Also, expect a binary soon.
StaticMapGenerator for ASP.NET, First Teaser
Last night I got frustrated with the fact that I have no intellisense (nor compile time check) for locating static files like .js, .css and image files.
So I sat up and created a simple console application that can generate exactly that, out of the site’s filesystem.
usage:
D:\MyTools\StaticMapGenerator /site:D:\Dev\MySite
it generates a file called Static.Site.Generated.cs within the site’s root folder, and then I go and include that file in my web project.
No I can do stuff like:
<script type="text/javascript" src="<%= Static.Site.Include.Scripts.myscript_js %>"> </script><link rel="stylesheet" href="<%= Static.Site.Include.CSS.master_css %>" /><img alt="Ken Egozi" title="My Logo" src="<%= Static.Site.Include.Images.Logos.my_logo_png" />
How cool is that?
It works in every ASP.NET compatible web framework (MonoRail, ASP.NET MVC, even WebForms …)
The only prequisite is .NET 2.0 runtime.
Sorry for keeping it out of reach for the moment. I need a little bit of time to setup a svn repository to make the source public (it would of course be BSD/Apache2/MIT thing) and to upload a binary. No promises given, I’ll try to make it in the coming weekend, or even tonight, so stay tuned.
The code is somewhat naive, and certainly does not cover any edge cases, however it’s enough to work cleanly on the largest project I’m currently involved in (Music Glue). Patches to make it more configurable and able to handle more edge cases would be gladly accepted once it’s out.
One cool spot - as part of this, I have also implemented my tiny IoC container in 33 LoC.
It's My Turn To Build An IoC Container In 15 Minutes and 33 Lines
Last night I’ve built a nice new tool called StaticMapGenerator which is used to generate a typed static resources site-map for ASP.NET sites (works for MonoRail, ASP.NET MVC and even WebForms).
I’ll blog about it on a separate post in details.
Since I didn’t want any dependency (but .NET 2.0 runtime) for the generator and the generated code, I couldn’t use Windsor to IoC. That calls for a hand rolled simple IoC implementation
Ayende has already done it in 15 lines, but I wanted also to automagically set dependencies and have a simpler registration model.
so I’ve quickly hacked together a configurable DI resolver (a.k.a. IoC container) in 15 Minutes and 22 Lines Of Code. Call me a sloppy-coder, call me whadever-ya-like. It just works.
static class IoC {
static readonly IDictionary<Type, Type> types = new Dictionary<Type, Type>();
public static void Register<TContract, TImplementation>() {
types[typeof(TContract)] = typeof(TImplementation);
}
public static T Resolve<T>() {
return (T)Resolve(typeof(T));
}
public static object Resolve(Type contract) {
Type implementation = types[contract];
ConstructorInfo constructor = implementation.GetConstructors()[0];
ParameterInfo[] constructorParameters = constructor.GetParameters();
if (constructorParameters.Length == 0) {
return Activator.CreateInstance(implementation);
}
List<object> parameters = new List<object>(constructorParameters.Length);
foreach (ParameterInfo parameterInfo in constructorParameters) {
parameters.Add(Resolve(parameterInfo.ParameterType));
}
return constructor.Invoke(parameters.ToArray());
}
}Ok, I’ve cheated. You’d need using statements too, but you can see that I was generous enough with newlines …
Usage:
Given those:
public interface IFileSystemAdapter { }
public class FileSystemAdapter : IFileSystemAdapter { }
public interface IBuildDirectoryStructureService { }
public class BuildDirectoryStructureService : IBuildDirectoryStructureService{
IFileSystemAdapter fileSystemAdapter;
public BuildDirectoryStructureService(IFileSystemAdapter fileSystemAdapter) {
this.fileSystemAdapter = fileSystemAdapter;
}
}You can do that:
IoC.Register<IFileSystemAdapter, FileSystemAdapter>();
IoC.Register<IBuildDirectoryStructureService, BuildDirectoryStructureService>();
IBuildDirectoryStructureService service = IoC.Resolve<IBuildDirectoryStructureService>();You need not worry about supplying the BuildDirectoryStructureService with an implementation for the service it depends on, but only to register an implementation for that service.
Conditional Rendering, or I Do Not Want Analytics Code On Dev Machine
From time to time you’d want some of your markup rendered only on ‘real’ scenarios. For example, you wouldn’t want google analytics to track visits you do on your dev machine. Sometime you’d even develop while your machine is not even connected to the internet, and every page would try get the analytics script and will behave strangely.
In Monorail, the Request has a property named IsLocal, just for that. I’ve wrapped it in a nice ViewComponent.
public class GoogleAnalyticsComponent : ViewComponent{
public override void Render() { if (Request.IsLocal) return; RenderView("AnalyticsCode"); }}
Accompanied by the AnalyticsCode view template:
<%@ Page Language="C#" Inherits="Castle.MonoRail.Views.AspView.ViewAtDesignTime" %><script src="https://ssl.google-analytics.com/urchin.js" type="text/javascript"></script><script type="text/javascript"> _uacct = "MY_URCHIN_CODE"; urchinTracker();</script>
, that can easily be extensible to set the urchin code with a parameter.
Cool vs Uncool in programming languages
Have just read Ayende’s post about C#/Java vs Boo/Ruby.
Tried to comment, but then I decided it’s worth a post.
I’d say that the difference is MAF - Management Acceptance Factor
- Java and C# has the Big Names behind them, so managers are comfortable. Ruby and Boo does not, hence …
- Java is v6, c# is v3, while Ruby and Boo are v0.x - another Management Scary.
Boo is also a way too cool/strange/creepy name for a distinguished suit to grasp.
It’s like when you’re a collage girl, and you want to introduce your new boyfriend to your mama. It doesn’t matter that he has a BSc and MBA plus 3 castles in the Swiss alps. If he’d first show up to the family on his way-too-cool motorcycle, then you’re going to be grounded.
When I approached my last manager about MonoRail, and told him that the views will be written in ‘Boo’, he got all scared. Then I wrote AspView, views to be written in c#, and he gave consent to go MonoRail.Even though, at least at that time, Brail was way more mature than AspView.The ‘cooler’ languages needs to be marketed to management.
Ruby works in Eclipse. I wonder who is going to start an OSS effort to create a decent Boo plugin for VS2008 (based on the VS2008 shell).
Make it demoable, make it look ‘official’, and MAF would go way higher.
Using the CodeGenerator and the DictionaryAdapter
Following users requests, I have just posted two documents to using.castleproject.org.
The first is an explanation about the CodeGenerator (from Contrib), and another one, on using the DictionaryAdapter.
Here are the links:
- http://using.castleproject.org/display/Contrib/Castle.Tools.CodeGenerator
- http://using.castleproject.org/display/Comp/Castle.Tools.DictionaryAdapter
Related stuff:
HOWTO: Make Windows Live Writer Output XHTML Markup
Problem:
- The output you get from Windows Live Writer is not XHTML, i.e. unclosed br and img tags.
Possible causes:
- When you’ve setup your blog in Windows Live Writer, you have used a version older than Beta 3
- Your blog’s style couldn’t have been detected by WLW
- Your blog’s style was been detected correctly, however you do not have a valid XHTML DOCTYPE declaration in your blog
Setting XHTML output manually:
-
Weblogs Edit Weblog Settings Advanced Markup Type
Thanks Mr. Joe Chang, from the Windows Live Writer team, who have pointed that out for me.
AspView for Castle RC3 - new release
Although about three weeks too late, I present thee:
AspView, builtfor Castle RC3 (release, debug, source)
I’ve also introduced a well due improvement to the engine. Now it supports the use of a 404 rescue view, that would get rendered in case of the url mapping to a non-existent controller.
the commit comment (for revision 314) says it all:
Handling view creation for EmptyController, specifically when a controller is not found and a 404 rescue exists
Next improvement will include an option for doing AutoRecompilation in memory, as sometimes the IIS process gets hold on the CompiledViews assembly files (dll and pdb) and failing the automatic recompilation process.
I certainly need that as it happens on my machine too much, and building the Web project takes a solid 10-15 seconds, while running vcompile is a milliseconds thing only.
Soon …
IE7 to the masses - the end of IE6 compatibility issues?
That’s a great news for everyone who build websites and web applications.
IE7 would be installable even to XP users without the Genuine Check.
That means that in short time, the IE7 adoption rate would increase so much, that hopefully the annoying IE6 would become as obsolete as Netscape 4 and IE 5.5 …
No more dirty CSS hacks (or at least, a lot less)
No more buggy box-model
Finally we can use input[type=text] and the likes
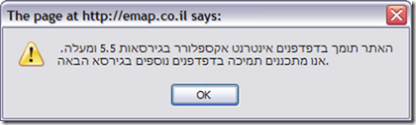
I’ve kept IE6 on my box for so long only to be able to test what I write. Even though I use Firefox for day-to-day browsing, I still need IE for some crappy israeli sites that would just not work on non IE (and by not work - I mean that you get an alert box saying:
For people who knows not Hebrew:
“This site supports IE browsers, from version 5.5 and up. Support to other browsers is planned for next release”
Ha Ha.
This message is there for at least a year.
And it’s not even dependant on ActiveX or other IE magic. It’s only some laziness regarding JS and CSS compatibility.
Yet Another xUnit framework for .NET
look at http://www.codeplex.com/xunit
Quite interesting. I might give that a shot soon.
You can read about it at http://jamesnewkirk.typepad.com/posts/2007/09/announcing-xuni.html
The upside for that isthe simplification of things by removing some attributes, and having a more consistent model regarding assertions on exceptions.
I'm Burned
Main reason - I want to reduce traffic to my blog (I do have a gazziliona million few hundredssubscribers, just like you, my dear reader.).
Plus, since feed-burner has gone Google-d, they give the PRO services for free, so I’d be able to enjoy the stats - which means I’d be able to know exactly how many people are reading me, and then can arrange the kenegozi-readers-party (thought about the Madison Square Garden, but I guess my living room will do just fine).
So, please update your favorite reader to point to http://feeds.feedburner.com/kenegozi.
Google Reader Is Even Better - They've Added a Search Box
Seriously, it’s Google. What took them so long?
Anyway - Google Reader remains my feed reader of choice. I do not use my laptop offline much, so it’s ok like that, plus the offline mode in reader kinda works, so for the occasional offline sessions I do have it’s more than enough.
It took me almost a week to notice, though …
VS2005 has lost grip of Resharper 3 Fonts and Color? re-install
I’m using VS2005 (with SP1, like duhh) and have had R# 3.0.1
Now, I’m not a fan of the default font and color scheme, as I like better the slicker mono-fonts, like Consolas. I am also becoming a Black-Background type, not for the WouldSaveTheRainForests==true reason (in LCD the light is static no matter what color it shows) but for the implements IDLikeToKeepMyEyeSightForALongTime reason.
So, started with importing a color scheme from some internet-found-place, don’t remember where, and then tried to change those Resharper coloring options (like, a variable name that is being used an odd amount of times, by internal classes, however not in an explicit-interface implemented method, that returns a struct), just to find out the the Fonts-And-Colors menu miss those lovely Resharper entries).
Okay, so what should I do? Export the settings, edit the xml, and re-import. Not much fun there.
Hmm. Googled it (I may use the term, as I actually use Google as a search engine), and found a post on jetbrains support site, with the same problem.no solution though.
However - this is how I solved it eventually:
-
Export the current settings toa file
-
Reset all settings
-
Re-install R# (hey - now it’s 3.0.2 !!)
-
Import back my settings.
Merging with TortoiseSVN
Assuming you have a main “trunk” in your subversion repository, and that you are actually working on a different branch.
You’d need to merge your changes from your branch to the trunk so other team members would be able to use your code. You’d also want to be able to merge from the trunk to your branch, to be able to use your teammate’s code.
The thing you should bear in mind while you merge, is that the actual merge process is actually working by generating a patch (using diff) and applying this patch on the target.
a quick note: It is very much recommended that you have committed all changes to the target of the merge, into the repository, so it would be easy to revert if something went wrong.
So: Merging from a branch to the trunk a. Go to the trunk folder on your filesystem, right-click->tortoise->merge.
b. You want the changes between the current trunk revision and your branch’s current revision to be applied on the trunk, so you choose:From: your trunk, revision HEADTo: your branch, revision HEAD.
I know, the terminology is confusing, as you want to “update” from the trunk to the branch’s state, but remember that you want the diff(erence), or in other words, the changes that will take the trunk FROM it’s current state, TO your branch’s state.
screenshot:
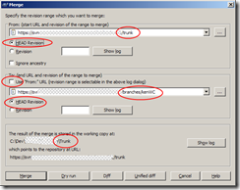
now you havea merged trunk on your workstation. Make sure that everything compiles and that tests are green, and commit. Merging from the trunk to a branch a) Go to your branch’s folder, right-click->tortoise->merge;
Now, you want the changes between the last trunk revision that you have on your branch, to the newest revision of the trunk. To find out that last trunk revision that you have on your branch, go to your branch’s folder, right-click->tortoise->show-log, and look for it. If you are a good reader you’d easily find it since you have mentioned the revision numbers of your merges in the commit remarks, as you are kindly recommended)A screenshot from the branch’s log:
I need to check if I have merged my branch to the trunk on a later point. I’ll do that using the Trunk’s log (trunk folder, right-click->tortoise->show-log):
Indeed. It seams that my branch is in sync with the trunk at revision 918
b) Now you fill From: your trunk, revision “last revision you have”To: your trunk, revision “new, wantedstate” (usually HEAD).in my example, the last trunk version I have merged into my branch is 902, so that’s the screenshot:
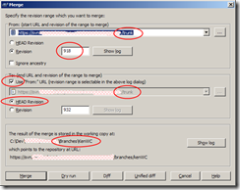
I know, terminology sucks again. You probably thing “from trunk to trunk? Is he crazy?” well, again, you want to get the changes that was made TO THE TRUNK, and apply them to your branch. Remembering that this is actually a patch that will get applied make anything clear again.
now you havea merged branch on your workstation. Make sure that everything compiles and that tests are green, and commit. Recommendation: write down in the commit’s remark, the revision number of the trunk (the current HEAD before the merge) for next time.
My thanks to this page, and to Lee Henson who have pointed it out for me, and helped my grasp the whole merge==diff’n’patch thing.
A Sign That I'm Starting To Like NHQG Too Much
Today I noticed that piece of code on my working copy:
Repository.Blog.FindOne(Where.Blog.Id == blogId)
Regionerate - c# region maker
Check out this nice tool from Omer Rauchwerger.
It could help a team to manage a coding convention. Should be very useful in Open Source environments. For example, when committing changes to castle project (or sending a patch) there is a coding standard than needs to be followed. Regionerate could help a lot with that effort.
I need to see if it can select methods and properties by attributes. It could then help making MonoRail controllers and ActiveRecord decorated classes more readable (region of all actions with a “SkipFilterAttribute”, region of “Property” and region of “HasMany”, etc.)
UPDATE:
Silly me, I forgot to mention that I found about this great tool at Roy Osherov’s blog. A very good one, that is. Many Agile related stuff, and funny little things, too. So go on and subscribe to it’s feed.
VS 2008 Javascript Intellisense + PrototypeJs => isFunToScriptBrowsers == true
Checkout the latest post of Scott Guthrie.
Is the long awaited JS IDE will be VS2008?
Now it’s a matter of adding ///<summery> tags to prototype.js and maybe people would really stop being afraid of developing javascript code.
Now that’s a good reason to switch to VS2008, combined with the fact than you can hold to your current .NET distribution.
Visual Studio 2008 will target multiple .NET runtimes
After all, even VS2005 was actually calling csc.exe rather that calling some magical inner stuff as in 2002/2003.
I hope that this also means better addin development support, so great projects like CVSI and ActiveWriter, could become even better.
Do you think they’d enable a “Compile for Mono” option?
AspView - a little bugfix
If you are an AspView user you might have noticed a problem.
If you setup a nullable-value-type parameter with a default value other than null, then you’d get a casting error.
example:
<%
int? someInt = default(int);%>
some markup
<% if (someInt == default(int)) DoSomething();%>
it happened because of the way GetParameter worked
GetParameter is a method that gets a view parameter value from the view’s properties collection (PropertyBag, Flash, Request.Params, etc.). It’s located inthe AspViewBase class (the base class for each and every view in the AspView world).
So, now it’s fixed, and a test was added to make sure it’ll stay that way.
As soon as google.com will be accesible again, you’d be able to check out and build.
UPDATE:
I’m too tired (3am here). The sources are on castle contrib and not on google, so you’d find them here
Google Gears - Local storage and Offline mode for Rich Internet Application
Wow.
Another great tool from Google.
Works on Win/Mac/Linux, for IE and FF.
In a few words - it can give you offline browsing, plus local storage using SQLite (so you can run SQL queries strait from your javascript to query the local store)
I wonder what secutiry issues can come up. However, it looks very cool, and can help bring power to existing DHTML/Ajax apps.
Makes me think. Now that you do SQL from javascript, isn’t it time forJsHibernate? and what about an ActiveRecord inplementation in javascript?
So, in the Flex/Silverlight war, it seams that Google is gonna win again …
(from Scott Hanselman’s Blog)
NANT 0.85 rc3 and .NET 2.0
I needed to manually Castle today, for the first time.
The need is for Castle.MonoRail.TestSupport.BaseControllerTest only, so I do not really care about all the rest.
Opened “How to build.txt”
I know that the builds in the CI server are failing due to some filing tests on DP2, so I add “-D:common.run-tests=false”.
no brainer.
I am also targeting .net2 only, so I add “-t:net-2.0”
baboom. This fails.
The nant exe is telling me that I can only build to .net 1.1, or .net compact framework 1.0.
So I went to nant’s config file, and found out to my surprise, that the frameworks that are present there are:
.net 1.1,
.net compact framework 1.0
.net 2.0 BETA 1
hmmm.
So I’ve edited the config, changed the existing .net 2.0 config name to .net2.0Beta1,
copy&pasted the .net node to another one, now switching version number from
sdkdirectory=”${path::combine(sdkInstallRoot, ‘bin’)}” frameworkdirectory=”${path::combine(installRoot, ‘v2.0.40607’)}” frameworkassemblydirectory=”${path::combine(installRoot, ‘v2.0.40607’)}”clrversion=”2.0.40607”
to
sdkdirectory=”${path::combine(sdkInstallRoot, ‘bin’)}” frameworkdirectory=”${path::combine(installRoot, ‘v2.0.50727’)}” frameworkassemblydirectory=”${path::combine(installRoot, ‘v2.0.50727’)}”clrversion=”2.0.50727”
voila. Now the build is starting.
However, the Castle.Components.Validator.Tests dll refuse to build. I’ll disable it, too.
UPDATE:
I’m an idiot. Did not notice that NAnt has gone far beyond rc3 a long time ago …
New feature to the blog - a blogroll
just added a blogroll.
To the DB, to the Domain, to the controller and to the view.
Took me (all in all) 30 minutes, including all the coding, CSS-ing, uploading to the webserver, setting up the DB table on the hosted server, adding a few entries, clearing the browser’s cache, and viewing it.
ah, and committing changes to Google code.
All of that was made in the Budapest Airport cafeteria, while waiting for my flight home (was a great trip. Photos, though not many of them, will be posted later on).
Rest assure that the DB access code is tested, and that the calls to the DB and to the cached data from the Controller and View are all typed.
I’d like to thank NHibernate, Castle and AspView (hey - that’s me !), who made this possible.
I bet Ayende would have done it in 20 …
Things my blog is missing
Since this blog is running on an engine that I wrote (available on Google code site, here), it lack some features that more mature blog engines already have. (the other engines lacks the combined power of ActiveRecord/MonoRail/AspView …)
So, that’s currently my list:
-
Blogroll, for obvious reasons.
-
Email alert for me when anyone posts a comment for one of my posts.
-
Comments feed (via ATOM).
UPDATE - Done
-
Email subscriptions for new posts, or new comments on specific posts.
-
I have a problem with the font. I should fix the CSS but the Internet connection here (I’m at a Budapest hotel) is quite poor. Will be fixed next week.
UPDATE - Done
Any other suggestions?
note that I do not intent on implementing Pingbacks and Trackbacks, since those were littering my blog in the past.
NUnit.org seams down
So if you wanna download it, you should go directry to the NUnit’s page on sourceforge
A new version of AspView - 0.7
I’ve just commited to the repository a new version of AspView.
The main addition is “Auto Recompilation” feature.
This means that when you change one of the view sources, the application will automatically recompile the views upon the following request.
You enable the feature by adding the next attribure to the aspview config section in web.config:
<aspview .... autoRecompilation="true" ... > ...</aspview>
Breaking change:
If you happen to reference an assembly from the GAC (using the aspview configuration in the web.config) you need to add a hint for the engine, like this:
<reference assembly="MyAssemblyFromGAC.dll" isFromGac="true" />
Known issues:
-
You need to let ASPNET user (or the Application Pool user) a modify access on the bin folder.Note that if you use the inner WebServer of Visual Studio this should not be a problem, since in that case the web application runs with your user, that has the needed peremissions on the bin folder.
-
For a strange reason, after you change a view and do the F5 in the browser, you still see the old version, and only on second F5 will the views be actually recompiled and refreshed. I hope to fix it soon …
Download from here.
Sources are here.
Backing up a hosted SQL Server DB
As you already have probably noticed by now, I did some renovation on my blog.
Among other things, it is now being served froma SQL Server database, rather than form the daBlog xml files.
One caveat of this, is the fact that backuping the blog’s content became much harder. Since I have no access to db backups, I neede to find a way to generate the INSERT scripts that will enable me recreationg the content if it would be needed.
My first try-out was the Microsoft SQL Server Database Publishing Wizard, that I saw at Scott Gu’s blog
This tool is meant to create the script form a local dev db, in order to make it run on the remote one. Actually you can make it run on the remote one, nd save the generated sql file locally, for backup purposes.
I tried it up, but it send some nasty .NET break dialogs.It however managed to create A script, that I’m yet to check for it’s usability.
Nice tool. But I’ll look for something that is pure t-sql so it’d be easier to run (maybe automated every once in a while)
The system administrator has set policies to prevent this installation
Another dumb error message.
While installing ActiveWriter, it asked me to install DslToolsRedist. Trying to do so raised the said error message. I was on my way to shot the admin, but then googled a bit, and found out on http://www.appdeploy.com/messageboards/tm.asp?m=8872&mpage=1that it is caused by prior installations of he same product that was not fully removed from the registry while uninstalled. Searching “DSL” in HKEY_CLASSES_ROOT\Installer\Products\ showed me that a previous CTP left some dirt in my registry. Removed that key, reinstalled DslToolsand the ActiveWriter magic could finally started.
ActiveWriter - 2nd preview is out
ActiveWriter is a VS2005 plugin, that adds a new item type for your projects. This item is actually a visual designer for ActiveRecord classes. Quite neat, and hopefully will increase the penetration of Castle’s ActiveRecord to the “If there’s no VS wizard, I do not use it” kinda guys.
You can read about it and download it from http://altinoren.com/activewriter/
Reflector 5 is out
The best tool ever is even better now, and you can find it here.
Thanks to Yosi for the reference.
Duck Type in .NET
There is a great article on CodeProject, by Guenter Prossliner.
A simple class in presented there, that makes Duck Typing possible for Generics enabledCLS languages (VB.NET 8 and C#2.0 for instance).
I’ll present it here in short form:
let’s say we have two classes:
1: class Foo1 2: { 3: publicstring Bar() { } 4: } 5: class Foo2 6: { 7: publicstring Bar() { } 8: }
Now you have a method that can work with instances of eiether one, and invoke Bar on it:
1: void SimpleMethodOnFoo1(Foo1 foo) 2: { 3: foo.Bar(); 4: } 5: void SimpleMethodOnFoo2(Foo2 foo) 6: { 7: foo.Bar(); 8: }
WATIR Recorder and running Hebrew watir scripts in Ruby
Just in case that Scott Hanselman’s blog isn’t accessible, I’ll post here the steps to use watir and WatirRecorder.
-
Install Ruby using the Ruby One-Click Installer, or search http://www.ruby-lang.org/en/for a newer version to download.
-
Install watir:A.By opening cmd.exe and typing “gem install watir” (will install the latest available gem version, which is a kind of a “live update” and “live download” feature of ruby, OrB. By installing watir-1.4.1.exe (792.19 KB), OrC. By downloading from here
-
Install WatirRecorder++
Some problems I’ve faces during the use of Watir:
-
The WatirRecorder couldn’t run my recorded tests. So I’ve saved the script to afile, changed it’s extension to .rb and let Ruby run the test.
-
This led to another problem. For some reason, Ruby doesn’t handle hebrew characters sowell when they’re saved in UTF8 format, and that’s the format WatirRecorder saves the scripts, So if you are recording hebrew characters toyour script, then after saving the script to a file and changing it’s extension to .rb, open it in notepad and resave it in ANSI encoding, and Ruby will run the test flawlessly.
Thumbs up for the makers of Ruby, Watir and WatirRecorder++, as well as to Scott Hanselman who’ve pointed this tool out for us